How We Use LLVM to Speed Up Generation of Reports

With business applications, it is vital to quickly generate the desired reports. To achieve this, it is important, among other things, to retrieve the result of a query (often a very complex one) from a DBMS as quickly as possible. And it is not always easy, because thousands (if not tens of thousands) of users concurrently access this DBMS to read and write data.
To prevent a high load on the main DBMS, we have created a database copy mechanism that copies data (all or part of it) from the main database to a separate one intended specifically for creating reports. Users can build reports with this dedicated database, getting results faster and without affecting the main database.
To further speed up the report generation process, we have developed the Data Accelerator, an SQL-compatible in-memory database, designed to guarantee maximum performance on OLAP tasks. The Data Accelerator can be used as a "reporting database" allowing significantly faster (sometimes ten times or more) generation of reports.
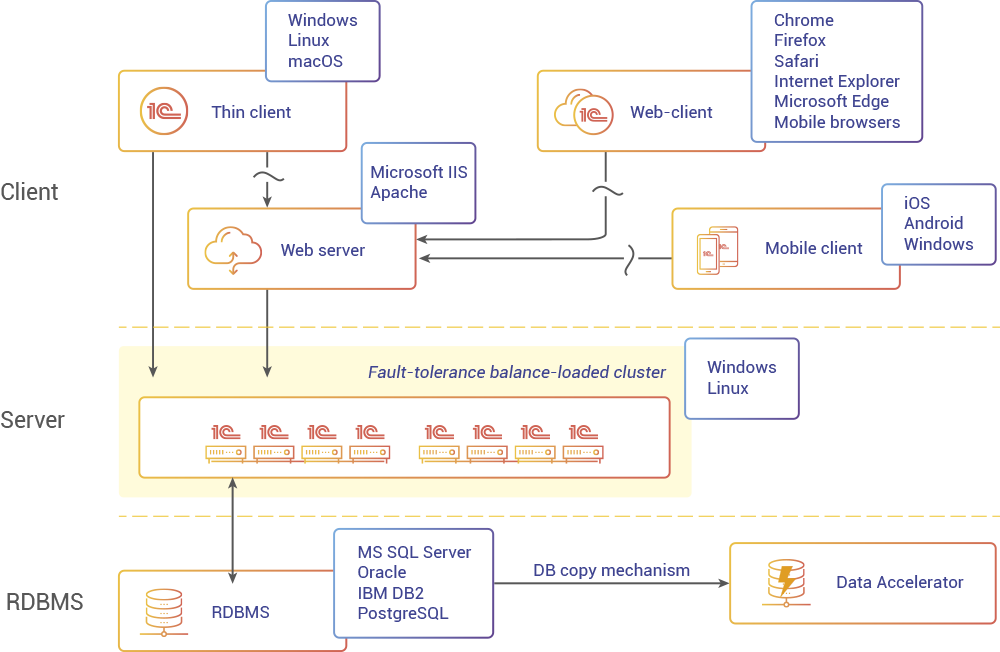
During the development of the Data Accelerator, we, of course, could afford to miss the opportunity to speed up the handling of queries using JIT compilation. To do this, we use LLVM, a project that, due to its accessibility, openness, and active development, has become the de facto standard for tasks of this kind.
There is plenty of information on the Internet about LLVM and the intermediate representation (IR) it is designed around, so in this article, we want to focus on how we generate the code to run high-level SQL queries and how to manage this code.
JIT Compilation
JIT compilation is a way to increase the performance of software systems when running previously unknown code by compiling specialized machine code while the system is running. When dealing with the Data Accelerator, the previously unknown code are SQL queries coming from the 1C:Enterprise platform as part of the report generation process.
JIT compilation in our case acts as an alternative to interpretation, where the system has a set of pre-compiled generalized algorithms that can be combined in any desired order and are capable of handling any data. Unfortunately, this approach brings a high system load with it that leads to decreased performance.
Compiling the code in parallel with query processing makes it possible to create highly specialized versions of algorithms that "know" exactly the type of data they handle and how to do it. It means that the algorithms contain neither redundant code nor unnecessary checks that can slow down the system significantly.
The Overview of the Query Processing System.
When processing a query, the Data Accelerator adheres to the scheme that is standard for most DBMS:
- parsing (lexical and syntactic analysis, checking the existence of tables and data typing, building the initial logical query plan);
- optimization of the logical plan;
- building a physical plan (selection of algorithms for various operators, splitting the request into individual tasks);
- query execution.
Thus, the query execution system works with a physical plan that, in fact, is a task graph. Each task in this plan is a tree of operators, each containing the necessary algorithm and the description of how data is placed in tables and temporary structures.
The runtime system consists of two main engines: the interpreter engine and the code-generating one that utilizes JIT compilation. The interpreter supports the full set of operators, and it is the first one to get all new functionality. As for the code-generating engine, it does not make sense to implement all operators in it. Some of them work with a small amount of data, and others may contain complex but little-changing logic, where code optimization to accelerate the process will not cover the efforts spent on generating and compiling code. Splitting a query into individual tasks allows us to flexibly distribute its processing to the most suitable engines.
Query Code Generation
We find the Volcano Execution Model extremely useful for writing interpreters. Per this model, each operator is implemented as an iterator with a single interface, which generally consists of methods Open, Next, and Close that allows combining iterators in any desired order. Execution in such a model starts from the topmost operator that, under its logic, calls the methods of child iterators.
However, for generated code, it is reasonable to stick to so to say opposite approach. We convert each original operator into a single section or several ones nested one into the other. The code is based on sections (loops) created out of operators that read data, including scanning of tables, reading temporary structures, hash tables, and the like. The rest of the operators get converted into sections and nested inside the loops. To control thread execution within a section, we can use break and continue for the desired loop.
In this model, the process starts with the lowest data read operator, while the top tree operator is nested inside the innermost loop and passively consumes the data that has reached it.
Let us consider the following query as an example:
select * from T1 inner join T2 on T1.a = T2.a
A schematic physical plan and the resulting hierarchy of code generation sections for it are shown in the illustration:
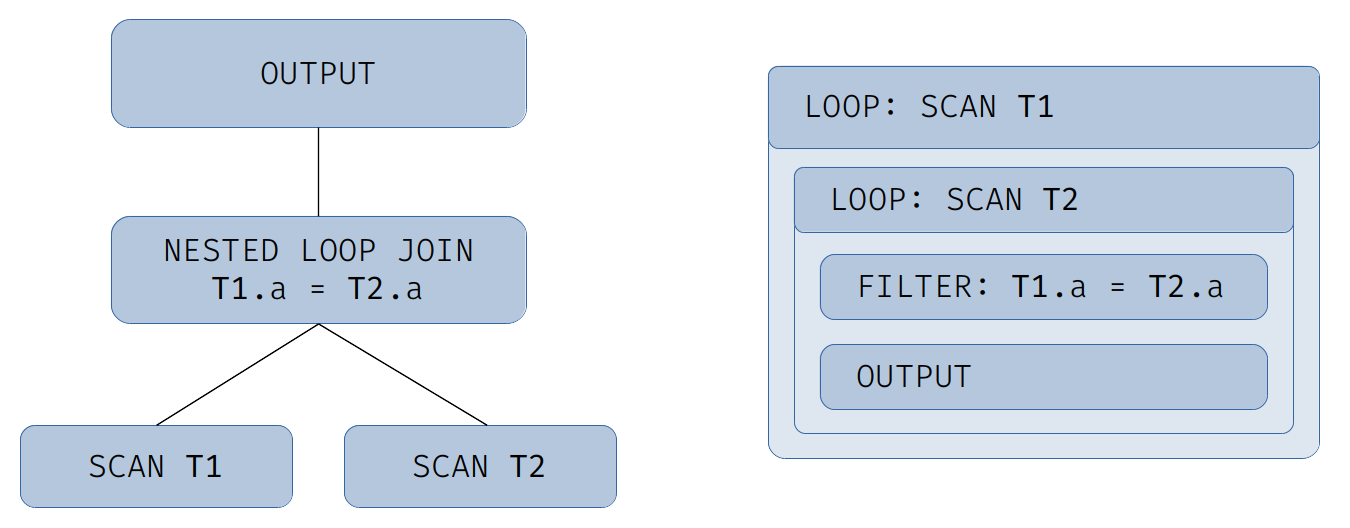
The result of the generation can be presented as the following pseudocode:
for (row1 : T1)
for (row2 : T2)
if (row1.a != row2.a)
continue
output(row1, row2)
Imagine that instead of a universal database you want to create a set of functions that perform specific operations on data of a previously known structure. The above pseudo-code is very similar to what a human person would do to code such an operation. Tables can be arrays of predefined structures, comparisons can be built-in language operations or additionally implemented functions, and so on.
What are the advantages of this approach? First, the structure of the resulting code is close to the usual code that developers write, which means that the LLVM optimizer is familiar with it and can apply the entire arsenal of its optimizations.
Second, unlike generalized operators in the iterator model, most of the operators that work with specific data are represented as individual code fragments and it improves the efficiency of branch prediction algorithms used in modern CPUs.
Third, in contrast to the iterator model, where each subsequent operator receives from the underlying one a data tuple, the structure of which is hidden, in our case we can adapt the operator code to specific purposes in various branches of the algorithm. For example, for operator Left Outer Join, when a row from the left table does not match in the right table, the right side values get substituted with null. Here we can generate two versions of the loop body: the first one will be used for the right side that has null values only, and the second one will be used for standard data of the right table.
A Large Query does not Always Mean a Lot of Code
Business applications with complex logic can generate very large database queries. But such queries do not always result in a large amount of generated code. Let's take a look at some techniques we can use to do this.
Reusing the Results of Algebraic Expressions. Repeated fragments of algebraic expressions are a pretty common occasion for queries. Assume we have one result field that is a complex expression made up of several columns, and the second is a similar expression that differs in an additional operation. Here, we extract identical sub-expressions, evaluate them once, and reuse the result as needed. Consider the following example.
select a + b, (a + b)/2 from T1
In such a query, we extract the expression (a + b) and evaluate it once instead of twice.
We run the analysis with the assumption that a conditional visibility setting is applied to the result. For example, if a sub-expression is in the branch of operator CASE, we can reuse it within that branch, but not in others:
select
case when c = 1 then a + b
when c = 2 then (a + b)/2
end
from T
In such a query, the expression (a + b) from the first branch of operator CASE cannot be reused in the second branch, since they have different conditions.
In theory, this optimization could be done earlier at the general query optimization stage, but in practice, it may require new operators to be inserted into the query plan which will result in plan bloat. As a result of this optimization, for some queries, the amount of generated code is reduced up to 4 times.
Placing Parts of the Code into Individual Functions. The adaptation of code per specific task in different branches of the algorithm as described above, can lead to unpleasant consequences if used unwisely. For example, when generating code for a sequence of nested Left Outer Join, you can get exponential growth in the amount of code (depending on the number of the Join operators). This can happen because the first operator generates two copies of the nested operators, each of them, in turn, generates two copies of subsequent operators, and so on.
To prevent code bloat, we keep track of the size of the resulting functions and, if necessary, automatically move parts of the code into individual functions. Not only it reduces code size but also makes it easier for the LLVM optimizer to handle compact functions more efficiently and, if possible, inline functions where it can give the greatest benefit.
Optimization and Compilation
The result of the generation process is an LLVM module containing the LLVM IR code. Before running the code, it must be optimized and compiled.
The LLVM offers several standard levels of optimization. These are the equivalents of flags from -O0 (no optimization) to -O3 (maximum optimization) familiar to users of the GCC and Clang compilers. It is also possible to choose your own set of optimization algorithms and the order in which they are applied.
In general, our experience shows that the performance of the resulting machine code can rarely significantly exceed the results acquired with standard sets of optimizations. Still, we can speed up the optimization process itself. The thing is that the generated code has several features that distinguish it from the "natural” one, written by a person. First, it is a large number of branches, often with trivial or constant conditions, as well as the general overcomplexity of the execution graph. LLVM has ready-made optimizations in its arsenal to handle these problems exactly. These are the optimizations aimed at removing unreachable code and simplifying the execution graph. Applying these optimizations early on greatly simplifies the code and speeds up the standard optimization process.
As every developer dealing with compiled languages knows, compilation, especially with a high level of optimization, is not the fastest process. But our task is to run queries quickly, which means that we cannot afford to sit and wait for the code to compile even for a second. There are several ways to speed up this process.
Since the query plan consists of individual tasks, we can generate and compile the code for these tasks in parallel.
The splitting of code into functions described in the previous section also speeds up compilation, since many LLVM optimization algorithms work much faster with small functions.
And finally, we can vary the level of optimization depending on the size of the resulting code: if, despite our best efforts, the size of the function turns out to be too large, we can reduce the level of optimization. Thus, we partially sacrifice the performance of the compiled function but significantly gain in compilation time. Of course, assessing this balance is an individual and difficult task.
Code Reuse
Despite all the tricks to reduce the compilation time, the ideal solution would be to avoid the compilation itself. And we can do it thanks to caching. LLVM allows you to keep the compiled code in memory along with some control structures, and, if necessary, free up the memory occupied by the code by removing old entries from the cache.
Also, splitting a query into individual tasks allows using a cache with higher efficiency. The code for each individual task is cached independently and can be used in other queries, provided that the respective tasks match.
It also opens up a lot of room for optimization. For example, queries often differ only in the values for constants. In this case, you can compile a generic version of the code, and pass the actual values into it as parameters. Such optimizations are some directions for our further work on the JIT compilation system.
Testing
It is time to see what practical effect JIT compilation of queries offers. To do this, we take queries from the TPC-H benchmark, which is considered one of the industry standards for comparing analytical DBMSs. This benchmark generates 8 data tables and includes 22 queries.
In order not to clutter up the graph, we limit ourselves to the first ten benchmark queries. We measured how many times faster the system can complete a query with JIT compilation vs the query with the interpreter. To demonstrate the compile-time impact, two results are shown for each query, with and without code caching. The graph scale is logarithmic.
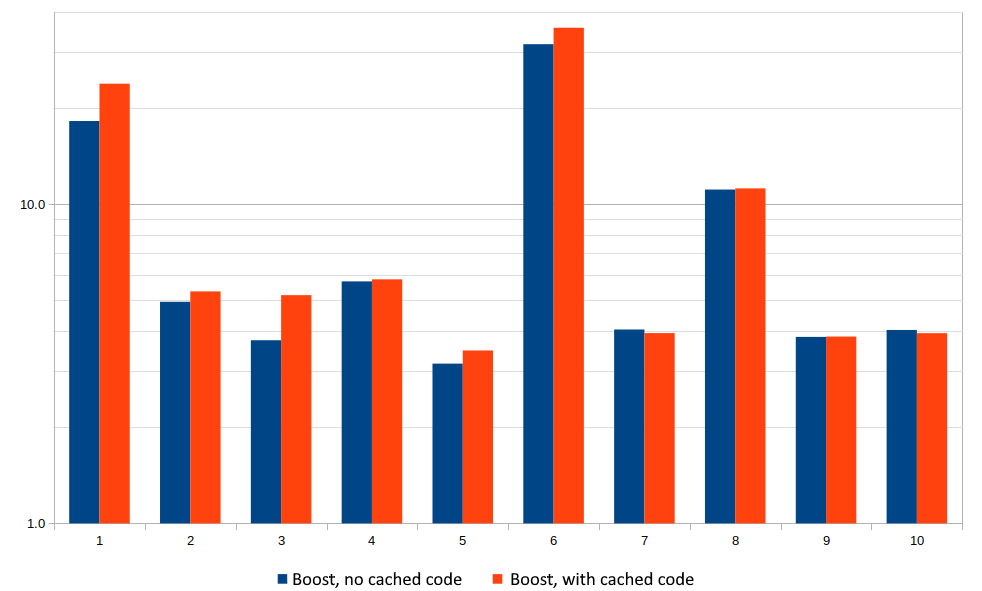
X-axis is the number of the query in the query set, Y-axis is the processing boost in the logarithmic scale.
A typical boost varied from 3 to 5 times, and in some particularly successful cases, code generation gave a gain of tens of times. As you can see for many queries, the difference between running with and without the code cache is within the margin of error. This is partly due to the speed of compilation, and partly to the fact that the execution of some tasks goes in parallel with the compilation of code for others. However, even in these cases, caching can reduce the consumption of computing resources.
Conclusion
JIT compilation of queries is a promising method for increasing DBMS performance, and in combination with the in-memory data storage model, it is one of the key technologies that provide high performance for the Data Accelerator. In tests and real-life applications, the Data Accelerator does real-time processing of up to tens and hundreds of millions of rows in databases of up to several terabytes in size.

Writen by


