1C Server Cluster. Part 1. Cluster Architecture
Throughout its history, 1C has consistently emphasized that its software products are designed to automate enterprise accounting. Whether it’s a small retail shop, a medium-sized logistics company, or a large manufacturing plant, 1C’s platform can automate the accounting processes for businesses of any profile.
However, a question often arises for those unfamiliar with the platform: How does the performance of 1C-based solutions hold up in large-scale enterprises? It’s one thing to run a program in a small shop with two or three workstations, but quite another when thousands (or even tens of thousands) of users are working simultaneously. Won’t such a large number of concurrent users cause issues?
To answer this, let’s dive into the history of the 1C platform’s development.
Initially, 1C products were designed solely for automating accounting, with data stored in DBF files. Naturally, this limited the number of concurrent users who could work with the system.
As the platform evolved, 1C introduced support for storing data in SQL databases. This significantly boosted system performance for multiple concurrent users, but even then, it could only handle dozens of simultaneous connections (not thousands or more). The limitation stemmed from the platform’s two-tier architecture: data was stored in the SQL database, but all business logic was executed on the client side.
To address this, 1C transitioned to a three-tier architecture, where the client application communicates with a 1C Server, which, in turn, interacts with the database server.
This allowed developers to split application logic between the client and the server. For instance, complex calculations or resource-intensive database queries could be executed on the 1C server, while user interface-related code ran on the client.
This shift to a three-tier architecture greatly improved the platform’s performance and increased the number of concurrent users it could support.
However, challenges remained. The first version of the 1C Server was a monolith (a single process handling all user connections). This process either delivered data to clients or interacted directly with the database. If an error occurred during code execution, the entire process would crash, taking down all client connections with it. In such a setup, fault tolerance was nonexistent.
Learning from these issues, 1C further evolved the platform by splitting the server process into multiple independent processes. The monolithic server was replaced by three types of processes: a worker process to handle client connections and two auxiliary processes to support cluster operations. This marked the introduction of a basic server cluster.
According to 1C’s official definition:
The 1C:Enterprise Server Cluster is the core component of the platform that facilitates interaction between users and the database management system in a client-server configuration. The cluster ensures uninterrupted, fault-tolerant, and concurrent operation for a large number of users working with extensive information bases.
Key features of the server cluster:
- It can operate on one or multiple servers.
- Each server can run one or more worker processes to handle client connections within the cluster.
- New client connections are assigned to worker processes based on their workload statistics, connecting to the least loaded or most efficient process.
- Cluster processes communicate with client applications, each other, and the database server via the TCP/IP protocol.
- Cluster processes can run as either applications or services.
General Client-Server Workflow
In the client-server model, the client application interacts with the server cluster, which, in turn, communicates with the database server.
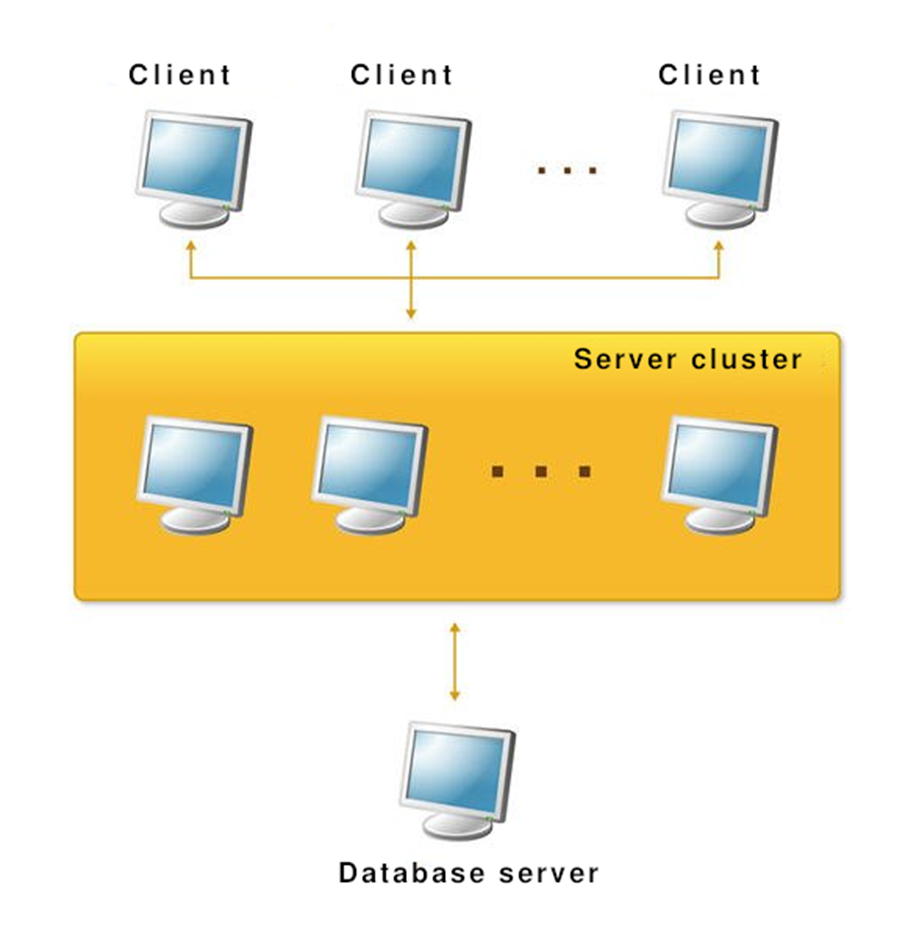
One of the servers in the cluster acts as the central server, which, in addition to handling client connections, manages the entire cluster’s operations and maintains the cluster registry.
To connect to the cluster, a client application only needs the address of the central server. Upon connection, the central server analyzes the workload of worker processes and directs the client to a specific worker process (either on the central server or on another server in the cluster). This mechanism enables load balancing across multiple servers.
The assigned worker process then authenticates the user and manages the connection until the session with the information base ends.
In its simplest form, a cluster can run on a single server with one worker process:
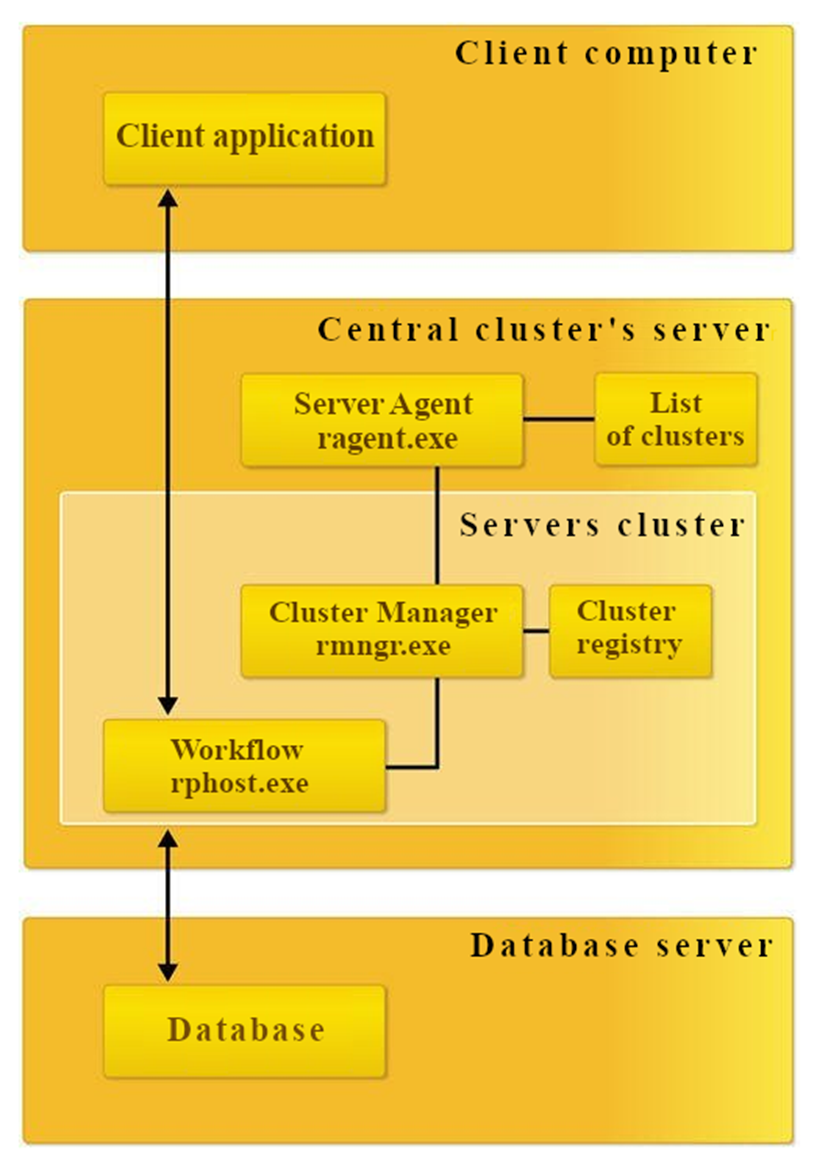
- rphost.exe: Worker process that serves clients and executes application code. It interacts directly with client applications and the database server, running server-side module procedures. A cluster can include multiple worker processes, potentially running on different physical servers, enabling scalability.
- ragent.exe: Server agent process that launches other processes and maintains the list of clusters on the server.
- rmngr.exe: Cluster manager process that oversees cluster operations. A cluster may have multiple manager processes, with one designated as the main cluster manager and others as auxiliary. The server running the main cluster manager, which also hosts the cluster registry, is called the central server. The main cluster manager maintains the cluster registry.
This overview briefly covers the structure and architecture of the 1C:Enterprise Server Cluster. In the next part, we’ll explore how the cluster ensures fault tolerance, scalability, and cross-platform compatibility, as well as dive into cluster administration.

Writen by
1C Developer
20+ years of experience in the software industry in Russia, UAE and Germany. My main fields of expertise are developing and implementation of business applications (Retail, CRM, WMS, and Accounting) and integration of software with POS equipment and web portals.


