Designing Business Applications with the 1C Platform Algorithms. Part 1.
![shutterstock_1065002318 [Converted]-01.png](/upload/medialibrary/9fc/9fcd61876f969194c849e508be8a05b4.png)
Introduction. How the 1C Platform Stores Data. Accumulation Registers.
Our website https://1c-dn.com has a significant amount of study materials describing how the 1C platform and its mechanisms operate. Some of the articles feature program code samples of wide-ranging complexity. However, all the materials have two drawbacks: platform mechanisms are described in isolation from their program implementations, and existing program code samples do not explain how the mechanisms work.Today we’re launching a series of articles that will address this deficiency. Each publication will include some explanation of how a mechanism operates within the 1C platform and some practice tasks to help you learn how to write a piece of code.
Let’s start with the basics, i.e., how the 1C platform stores data. But first, I’d like to remind you that 1C is not a universal programming language like Java but rather a specialized tool used to rapidly design business applications. Sometimes the 1C platform is described as a special-purpose framework for the design of business applications. The reason for it is that the platform already has mechanisms that save developers from thinking about the number of SQL tables to create (one vs. multiple ones). Thus, 1C developers can enjoy designing an application at a higher level, namely the business logic level, where there is no need to directly handle database tables (SQL tables). Here they work with objects (or entities) called documents, catalogs, etc. Thus, we will talk about these objects most of the time but occasionally “drop” to a lower level where data is stored on SQL servers.
Let’s assume we need to automate operations in a company that buys products from suppliers, puts them in warehouses, and then sells such products at a markup. Naturally, the company management needs to have the latest information about the current situation: warehouse inventory, sales value for a given period, accounts payable, and, most importantly, profit. We’ll break the task down into parts and start with warehouse inventory accounting.
Let’s stop here and take some time to think about how should a business company operate when accounting is done manually. I imagine it something like this. A clerk receives a supplier invoice as proof of warehouse delivery and places the invoice into a designated folder. When a manager needs to know how much inventory they have at their warehouse, the clerk takes all invoices, calculates the total number of products specified in them, and hands the report to the manager. Here is how such data flow looks like:

First, the clerk receives documents. Then, at the manager’s request, the clerk uses the documents to generate a report. In other words, with this arrangement, all data is kept in documents, and when there is a need to analyze such data (say, check current stock), they have to collect and process all such papers.
Let’s see how we can apply this approach with SQL. In this case, an invoice corresponds to INVOICES SQL table.
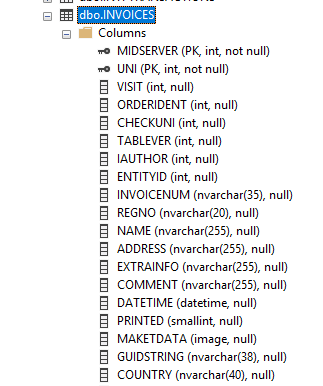
It seems easy enough. We can always sum up the values we want (like stock balance in our case) using SQL server tools and generate the required report. But let’s now assume that our company receives hundreds of supplier invoices every day, and this company has been running for years. The INVOICES SQL table will constantly be growing in size. As a result, with each day, it will take more and more time to generate reports. This is due to the need for an SQL server to sum up data for the entire company’s operations before producing the stock balance report. We must admit that it’s pretty impractical. Even more, it looks pretty much like a dead-end. The benefit of the 1C platform is that it offers a solution to optimize data handling. In the diagram above, we want to add one more type of object between documents and reports. We call them registers.

Here is how it works. Our clerk keeps on processing suppliers’ documents as before and puts them in a folder. However, from time to time, for example, when there is some spare time, the clerk returns to finalized documents, estimates how many products are currently available at the company’s warehouse, and writes down obtained figures in a particular book. On management’s request to report available stock, the clerk opens the book and gets the latest number instead of worrying about having to process a huge number of invoices. It means that the report gets generated much quicker no matter how many processed documents we have under consideration.
In other words, the clerk has an intermediate place to store the data, which is then used to generate new reports.
The principle of storing data in an intermediate place is the foundation of the 1C platform. The difference is that we replace the clerk’s book for storing the calculation results with an object called an accumulation register.
Note that the 1C platform has several objects that are called registers. They are accounting registers, calculation registers, and information registers. All of these objects are important, and we want to discuss them all in due time. However, accumulation registers are the most significant ones as they ensure data handling by the platform mechanisms.
So, the 1C platform has a mechanism allowing to store data outside of documents. Naturally, you might want to ask a couple of questions. What kind of data can you keep in a register? How does data end up in a register? How many registers could there be in a system? I’ve got the answers.
Let’s assume we have a supplier invoice as a 1C document. It has multiple attributes: document date and number, products delivery date, a warehouse that received the products, supplier’s name and corresponding contract, a shipping company that delivered the products to the warehouse. What attributes do we need to create a list of products on stock, including the quantity of each product? It’s a simple question as we only need to know a product name and available quantity. Here is the data structure we arrive at:
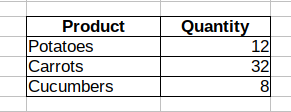
Let me remind you that we require no additional data to estimate our warehouse stock balance. The data we already have is absolutely enough. In fact, we have now designed a structure for our future register. Naturally, a real-life register is a bit more complex than the one we use here, but this is enough to demonstrate the approach to data storage. In theory, a register can store any data and present it any way you want. However, there is a limitation: the fewer dimensions (attributes, fields) a register has, the higher read and write capacity it can provide. In other words, if we need just two fields (product and quantity) to estimate stock balance, we should use only these two fields and avoid adding the supplier field to this register.
The next question is how we put data in a register. Since registers are independent objects within the 1C platform, there is no automatic process for adding data. Developers should design a program code to write applicable data into a register. There is a specific process (or mechanism) in the platform for writing data. It is called posting.
Once again, posting is a mechanism that writes data into a register (or registers) after we add a document into the system.
In real life scenario, the clerk creates within the 1C application a supplier invoice document, fills it up with appropriate data, and clicks the Post button. By doing this, the clerk orders the system to record the document (and add relevant lines to DBMS tables) and then trigger the pre-defined posting procedure. Here how the applicable algorithm code looks like:
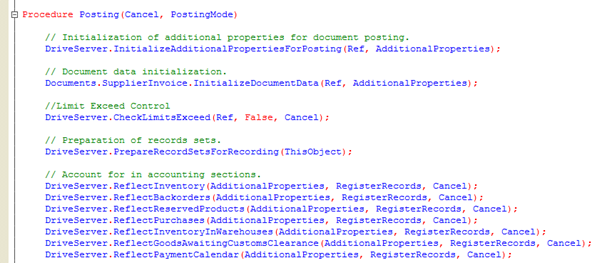
Still, we need to add some code of our own. The purpose of the code is to add records to applicable registers. Basically, the document posting procedure consists of two parts: recording a document and writing data into a register.
Those of you who dig deep should notice that we actually duplicate data as we write it into both the document and the register. At that, you might consider it to be a bad thing. And I cannot but agree. In theory, data duplication might result in a situation where document data and register data differ. For example, when posting a supplier invoice, we need to increase a product’s quantity in a warehouse. Nevertheless, a developer might make a mistake and decrease the value during the posting procedure. This is why developers have a great responsibility for designing correct and well-behaved code. On the other hand, using registers to store data and generate reports allows us to massively raise system performance as registers store normalized rather than redundant data. Do you still remember that we use just two attributes (fields) for stock balance: product and quantity?
The next question regarding the number of registers a system can have is a natural continuation of the previous matter. Let’s assume we have set up a register to store stock balance just as described above. And all of a sudden, the management tells us that we need to monitor accounts payable as well. What is the easiest way to complete this task? Can we simply add new fields to the register? Remember that we have designed this register specifically for stock balance. There is no structure to account for payments. What should we use as a solution? Is there any at all?
Sure, there is! We create one more register with a different (completely different!) set of attributes (fields) to store data relating to supplier-related payments. Based on data from this register, the management can obtain the latest data on accounts payable. As noted above, data doesn’t get added to a new register automatically. It needs to be arranged by developers. We can achieve it by modifying the posting procedure so that recording a document results in adding data to the new register as well.
As for the question on the limit of registers in the system, the answer is simple. You can add as many as the task requires. The main rule is that a register structure (in fact, data stored in a register is an SQL table used by servers to store data) must be normalized to ensure optimal writing and reading speed. It is the key condition to gain high system capacity.
Let’s now go back to the register that handles the stock balance. We have designed its structure, but, as noted above, a real-life register will be more complex due to additional service fields (attributes) it is likely to contain. Here’s how a document flow table in a register might look like:

Take a closer look at these service attributes (fields). It is evident that the period field (date type) reflects the date when information is added to the register.
The recorder field links the line to a document that is a source of data recorded to the register. This field is very important as it can take us to the document right from the register.
Another important field is record type. We need it to state whether we receive products from suppliers or sell them to our customers. In case of receipt, the 1C platform needs to increase product quantity in the register, and in case of a sale, the value needs to be reduced. Thus, judging by the context, you can see that the record type field denotes the type of transaction. For supplier documents, this is a receipt, and for sales documents, this should be an expense.
The last service field is line number, which is a line number in the source document. As supplier invoices have a table with data that gets added into a register, we need a line number to identify each line in a table.
Now let‘s take a moment and get back to tasks related to data storage and retrieval. Generally, there are two ways of accumulating data. Option 1 is to answer the question of how much has been accumulated up to a specific date, and option 2 is how much has been accumulated over a given period.
Thus, the first approach works for storing and retrieving data related to stock, like warehouse stock balance. At that, we can either add products in books (positive value for products movement or receipt) or write them off (sales, expense, or negative value for products movement or). It is precisely the storage method we used for designing this register.
Still, there can be a task of another type. Imagine we need to know the quantity of products sold in the last month. In this case, we’re not interested in the stock balance for a specific date. Instead, we need to know the quantity of products sold over a given period, i.e., turnover. To store this type of information, 1C uses a different type of register.
Technically, an accumulation register object on the 1C platform can be of two kinds, either balances or turnovers. We define it when creating a register:
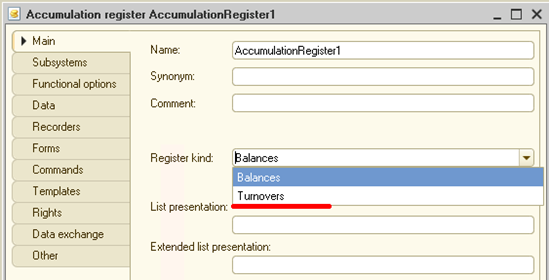
Based on this information, the register we are now designing (as you know, we want to use it for product balances) should be balances. This kind of register can have two types of records, namely receipt and expense.
Registers for turnovers deal with turnovers only and have no record type field. We certainly plan to give such registers sufficient attention but for now, let’s go back to the registers for balances.
We have seen that the processing power of the 1C platform comes through storing data in registers. Here is how a data storage structure of a standard register might look like:

Basically, it’s an SQL flat table. I imagine you asking, “Wait! Where does an improved processing capacity come from? Is there a difference between generating a report based on data received from an SQL table in a document or an SQL table in a register? Should not read and write capacity for both cases be almost the same?”
Here we gradually move to the second fundamental rule of data storage in 1C (the first one is storing data in registers). To ensure fast reading of data from registers (pay attention, I say READING, not WRITING), the platform automatically creates an additional DBMS table to store intermediate balances for each existing register (which, in fact, is a standard DBMS flat table).
What is this, and why do we need it? See the diagram below:
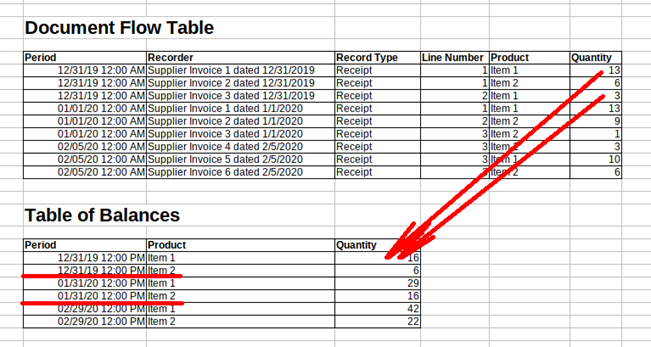
On top is the document flow table, which is the main table in the register. This is where we keep document posting data. The second table reflects balances that the 1C platform automatically draws up immediately after a developer creates a new register. At that, developers can’t add data to this table because only 1C can. What kind of data is it?
It is essential to know that this table holds total balances for each register’s dimension (field, attribute) valid for the end of each month. See the diagram again: the system calculated end-of-month balances for Item 1 and Item 2 products. Make sure you remember that that the 1C platform automatically calculates balances for each register. Neither developers nor users can interfere with this process. It’s vital to know and understand this.
OK, we’ve calculated total balances for each product, but how do we improve processing capacity by this? Let’s assume we need to know Item 1 balance as of February 6, 2020. If there is no table of balances, we have to process all the product receipts covering the period up to the date. As explained above, this approach slows the system down. However, if we use the table of balances, the data retrieval process speeds up dramatically. While we have balances for each month, we can use Item 1 balance for the end of January 2020 (29 items) and sum it up with the records added between February 1 and 6 (3 + 10 items). The total is 42:
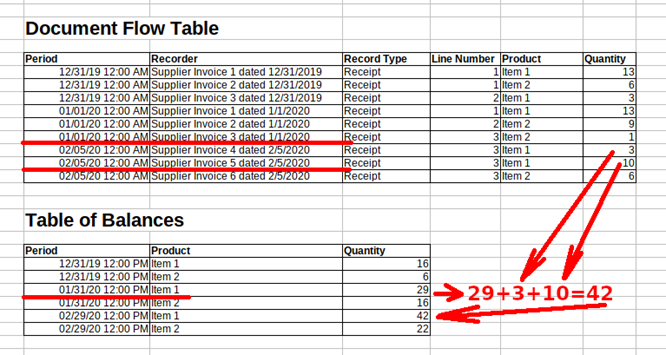
This example is pretty straightforward, but it illustrates how data storage and, most importantly, data reading in accumulation registers happens. With large amounts of data, the storage of intermediate totals means a considerable benefit in terms of performance.
Remember that the system automatically calculates all intermediate totals and requires no developer involvement. Data reading occurs the same way. We simply request data, such as Item 1 balance for February 6. The 1C platform auto-retrieves intermediate totals from the table for totals and adds up the records from the document flow table without any involvement of developers. It is this approach that makes the 1C platform so powerful and capable of handling vast amounts of data.
As noted above, there is one more type of accumulation register: the turnovers register. We need to discuss it in more detail a bit later. For now, just bear in mind that such a register does not have a table for totals (which is surprising, right?). Instead, the 1C platform provides a turnovers register with a table for turnovers. As well as in the case with a table for totals, a table for turnovers stores calculated monthly turnovers. When there is a need to retrieve a turnover value for a specific period, the platform retrieves computed data from the table for turnovers and sums it up with data relating to the unprocessed period. The algorithm is the same as with balances registers.
Well, I assume this is enough theory for a start. It is time to move to practical tasks. In the following article of the series, we will create a supplier invoice document, catalogs to store additional data, an accumulation register, and we will also write a program code for adding records in a register. In other words, we are going to do the things we have discussed today.
See you soon!

Writen by
1C Developer
20+ years of experience in the software industry in Russia, UAE and Germany. My main fields of expertise are developing and implementation of business applications (Retail, CRM, WMS, and Accounting) and integration of software with POS equipment and web portals.


