Eclipse as a technological platform for 1C:Enterprise Development Tools
probably needs no introductions. Many software developers learned about Eclipse when they started using Eclipse Java development tools (), a popular open-source Java IDE. When they say "Eclipse", they often mean the Java IDE. However, Eclipse is much more than that. It is an extensible platform for development tool integration (Eclipse Platform) and a whole range of IDEs based on that platform (including JDT). It is also the Eclipse Project, a top-level project that embodies the development of both Eclipse Platform and JDT, and the Eclipse SDK, the result of that development. Finally, Eclipse is an open-source foundation featuring a variety of projects, some of them are not even written in Java or related to development tools (for example, and ). The world of Eclipse is extensive and diversified.
This article aims to provide an introductory architectural overview of the Eclipse Platform and the other Eclipse components that form the foundation of 1C:Enterprise Development Tools (the new Designer). Of course, we cannot go deep into details because the article is intended not only for Eclipse developers. However, we hope it could offer something of interest even for the more experienced Eclipse developers. For example, it unveils one of the "Eclipse secrets", a relatively new and not yet well-known project initiated and maintained by 1C Company.

Introduction to Eclipse architecture
First, let us talk about general aspects of Eclipse architecture using (JDT) as an example. JDT is not a random choice, it is the first integrated development environment that became available in Eclipse. Other Eclipse *DT projects, such as Eclipse C/C++ Development Tooling (CDT), were developed later and they borrowed both main architectural principles and some code fragments from JDT. The basics of JDT architecture are applicable to virtually any Eclipse-based IDE, including 1C:Enterprise Development Tools.First of all, Eclipse architecture features distinct layers where language-independent functionality stands apart from the functionality that supports specific programming languages, and UI-independent core components stand apart from the components that provide the user interface support.
Thus, the Eclipse Platform defines the general language-independent infrastructure, while Java development tools add a fully-functional Java IDE. Both Eclipse Platform and JDT consist of multiple components, where each component belongs either to the UI-independent core or to the UI layer (see fig. 1).
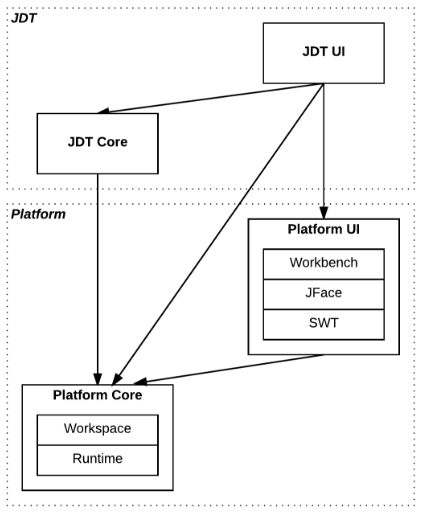
Fig. 1. Eclipse Platform and JDT
Major Eclipse Platform components include:
- Runtime — Defines the plug-in infrastructure. Eclipse architecture is module-based. Essentially, Eclipse is a collection of extensions and extension points.
- Workspace — Manages one or several projects. A project contains files and folders, which are mapped to files and directories in the file system.
- Standard Widget Toolkit (SWT) — Incorporates basic user interface controls that are integrated with the operating system.
- JFace — Provides a set of UI frameworks built over SWT.
- Workbench — Defines Eclipse UI paradigm: editors, views, and perspectives.
Core Runtime
The infrastructure of Eclipse plug-ins is based on and is implemented in project. Each Eclipse plug-in is an OSGi bundle. The OSGi specification defines, among other things, mechanisms for bundle versioning and dependency resolution. In addition to these standard mechanisms, Equinox introduces the extension point concept. Each plug-in can define its extension points and can introduce additional functionality (extensions) using its own extension points or extension points of other plugins. A detailed description of OSGi and Equinox is beyond the scope of this article; the point is that Eclipse is a completely modular environment (any subsystem, including Runtime, consists of one or several plug-ins) and almost all parts of Eclipse are extensions. Notably, the Eclipse architecture incorporated these principles long before it adopted OSGi (previously Eclipse was based on its own plug-in infrastructure that was conceptually similar to OSGi).
Core Workspace
Virtually any Eclipse Platform-based integrated development environment uses Eclipse workspaces. Usually, it is a workspace that stores the source code of applications being developed in the IDE. The workspace structure is mapped directly to the file system; it consists of projects that store files and folders. These projects, files, and folders are called workspace resources. The implementation of the Eclipse workspace serves as a file system cache, which significantly improves the performance of traversing the resource tree. In addition to that, the workspace provides some supplemental services, including and .
The Core Resources component (org.eclipse.core.resources plug-in) provides support for workspaces and their resources. In particular, this component provides programmatic access to the workspace in terms of the resource model. Efficient access to this model requires a simple way to represent references to resources for clients. However, the object that stores the resource state within the model should be hidden from clients. If this requirement is not met, in scenarios where a file is deleted, the client would not release the object that is no longer available in the model (and this would cause other issues). Eclipse solves this problem using resource handles. A handle serves as a key (it only stores the path to a resource in the workspace) and it fully controls access to the object within the model that stores the resource state. This design is a variation of the pattern.
Fig. 2 illustrates the usage of the Handle/Body idiom in the resource model. The IResource interface represents a resource handle and serves as an API. The Resource class, which implements this interface, and the ResourceInfo class, which represents the body, are not APIs. Note that a handle stores only a resource path relative to the workspace root and does not store a reference to resource info. Resource info objects form a so-called "element tree". This data structure is fully stored in memory. To find a resource info instance that matches a specific handle, the element tree is traversed according to the path stored in the handle.
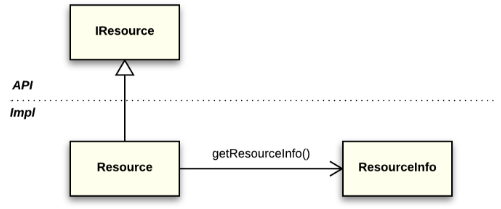
Fig. 2. IResource and ResourceInfo
As we shall see later, the handle-based design of the resource model is also used for many other models available in Eclipse. This design has the following characteristics:
- A handle is a value object. Value objects are immutable objects whose equality is not based on identity. Such objects can be safely used as keys in hashed containers. Multiple handle instances can refer to a single resource. To compare them, use the equals(Object) method.
- A handle defines resource behavior but does not store resource state, it only stores the "key" (the resource path).
- A handle can refer to a resource that does not exist (the resource is not yet created or it is already deleted). You can use the IResource.exists() method to check whether a resource exists.
- The implementation of some operations can be based solely on the data stored in a handle (handle-only operations). Examples of handle-only operations are IResource.getParent() and getFullPath(). Such operations can be successfully executed even if the resource does not exist. If an operation requires an existing resource, it throws a CoreException if the resource is not found.
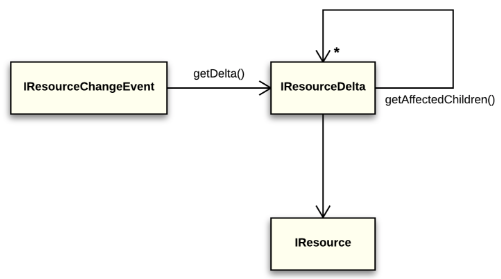
Fig. 3. IResourceChangeEvent and IResourceDelta
Delta-based notifications have the following characteristics:
- A single change and a set of changes are described by a uniform structure (because deltas are composed recursively). Subscribed clients can process resource change notifications using recursive descent through a delta tree.
- A delta contains a full change description, including resource moves or changes in "markers" associated with the resource (such as compilation errors).
- Since references to resources are handle-based, a delta can naturally refer to a deleted resource.
JDT Core
The resource model of the Eclipse workspace is a fundamental language-independent model. The JDT Core component (org.eclipse.jdt.core plug-in) provides an API for navigating and analyzing the workspace structure from the point of view of the Java language (the so-called Java model). This API is defined in terms of Java elements, unlike the underlying resource model API, which is defined in terms of files and folders. Fig. 4 shows the main interfaces of the Java element tree.
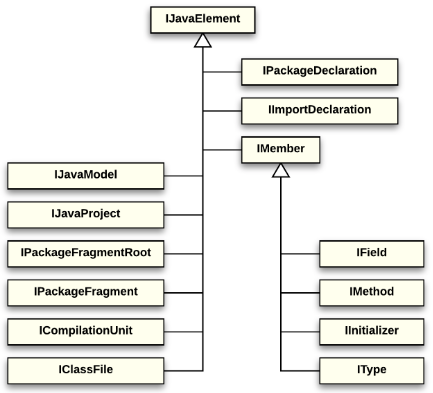
Fig. 4. Java model elements
The Java model uses the same handle/body idiom as the resource model uses (see fig. 5). IJavaElement is a handle, JavaElementInfo is a body. IJavaElement defines the protocol that is common for all Java elements. Some of its methods are handle-only, such as getElementName() and getParent(). The JavaElementInfo object stores the element state, which includes element structure and attributes.
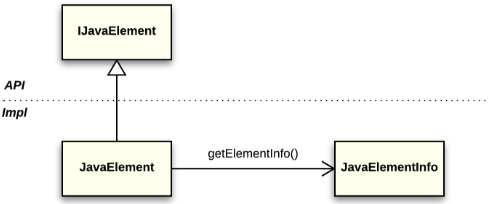
Fig. 5. IJavaElement and JavaElementInfo
Unlike the basic handle/body design of the resource model, the one used in the Java model is more involved. As it was mentioned before, in the resource model, the element tree, which consists of resource info objects, is fully stored in the memory. However, the Java model might include many more elements than a resource tree because it also stores the internal structure of .java and .class files: types, fields, and methods.
To avoid the need to store the entire element tree in the memory, the Java model implementation uses a bounded LRU cache of element info where IJavaElement handle serves as a key. Element info objects are created upon request during the navigation through the element tree. Rarely used elements are evicted from the cache, so the total amount of memory used by the model is limited by the cache size. This is another advantage of a handle-based design, which completely hides such implementation details from the client code.
Notifications about Java element changes are similar to notifications about workspace resource changes, which are described earlier in this article. To monitor the changes in the Java model, a client subscribes to notifications, where each notification is an ElementChangedEvent that contains IJavaElementDelta (see fig. 6).
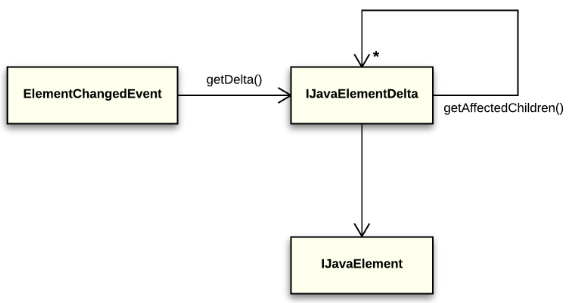
Fig. 6. ElementChangedEvent and IJavaElementDelta
The Java model does not contain any information about method bodies or name lookup. This is why JDT Core provides an additional model for a detailed analysis of Java code: (AST). This model is not handle-based. The AST provides the result of parsing the source text. AST nodes represent the source module elements (declarations, operators, expressions, etc.) and store the position of elements in the source text and, if applicable and requested, name lookup info as references to so-called bindings. Bindings are objects that represent named entities known to the compiler, such as types, methods, and variables. Unlike AST nodes, which form a tree, bindings support cross-references and generally form a graph. The abstract class ASTNode is a common base class for all AST nodes. ASTNode subclasses correspond to Java syntax rules.
Since syntax trees can occupy large amounts of memory, JDT only caches a single AST that corresponds to the active editor. Unlike the Java model, the AST is usually treated as an "intermediate" and "temporary" model, thus, clients should not keep references to the elements of this model outside of the context of the operation that generated the AST.
The three listed models (Java model, AST, and bindings) provide a basis for building "smart development tools" in JDT, including the powerful Java editor with a lot of code assistants, source actions (such as "Orgainize Imports" and "Format"), and search and refactoring tools. Moreover, the Java model provides a basis for various "structure views", such as Package Explorer, Outline, Search, Call Hierarchy, and Type Hierarchy.
Eclipse components used in 1С:Enterprise Development Tools
Fig. 7 shows the Eclipse components that form a basis of the technological platform for 1C:Enterprise Development Tools.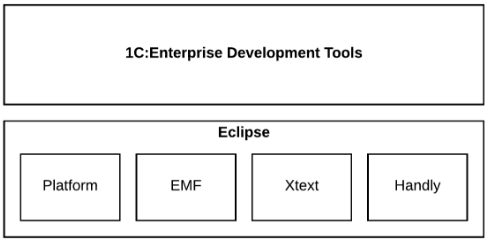
Fig. 7. Eclipse as a platform for 1С:Enterprise Development Tools
The Eclipse Platform provides basic infrastructure. We reviewed some of its aspects in the previous section.
(EMF) provides general tools for modeling structured data. EMF is integrated with the Eclipse Platform but can also be used in standalone Java applications. Even beginner Eclipse developers are often familiar with EMF. In a large part, EMF became so popular due to its universal design, which incorporates, among other things, a uniform meta-level API that enables access to any EMF model in a completely generic way. EMF provides base implementations of model objects and a subsystem that generates model code based on the meta-model, which significantly increases the development speed and reduces the potential for errors. EMF also includes facilities for model serialization, model change tracking, and much more.
Like any universal tool, EMF is suitable for solving a wide range of modeling tasks. However, some classes of models (such as the handle-based models described above) might require specialized modeling tools. Describing EMF in its entirety in a single article is clearly not practical; the subject is so extensive that it would easily fill a large volume. Let us just say that due to its high-quality universal design, EMF gave the origin to a variety of modeling projects. Together with EMF, these projects are a part of the top-level project. One of these projects is Eclipse Xtext.
provides an infrastructure for "textual modeling". Xtext uses for parsing the source text, and it uses EMF to represent the resulting ASG (abstract semantic graph, which is essentially a composition of AST and bindings; it is also called a "semantic model"). The grammar of languages modeled using Xtext is described in Xtext’s own grammar language. This allows Xtext not only to generate grammar description for ANTLR, but also to provide facilities for AST serialization ("unparser") and content assist, besides some other language-related components. However, Xtext grammar language is less flexible than, say, ANTLR grammar language. Thus, you might need to adapt your language to comply with Xtext. This is usually not an issue for languages being developed from scratch. However, this approach might not work for languages with established syntax. Still, currently, Xtext is the most mature, universal, and feature-rich Eclipse framework for building programming languages and the development tools for these languages. In particular, it is an ideal tool for quick prototyping of (DSLs). In addition to its ANTLR- and EMF-based language core, Xtext provides a lot of useful higher-level components (including indexing and incremental building facilities, "smart editor", etc.), but notably, it does not provide support for handle-based language models. Like EMF, Xtext is too extensive and deep to be covered in a single article, therefore we shall move on now.
1С:Enterprise Development Tools make active use of both EMF and other Eclipse Modeling projects. In particular, Xtext is a basis of the development tools for both 1C:Enterprise script and 1C:Enterprise query language. Another basis for these development tools is Eclipse Handly. We will tell more about it because it is the newest and, thus, lesser-known Eclipse component among those mentioned in this article.
, a subproject of a top-level Eclipse Technology project, was first contributed to Eclipse Foundation by 1C Company in 2014. At the present time, we provide support for the component (Handly committers are the employees of 1C Company). This small project occupies a unique niche in Eclipse: its main purpose is the support of handle-based model development.
Earlier in this article, we described the main architectural principles of handle-based models, such as the handle/body idiom, on the example of the resource model and the Java model. We also noted that both the resource model and the Java model are essential for Eclipse Java development tools (JDT). And since the architecture of almost all Eclipse *DT projects is similar to JDT architecture, it will not be a wild exaggeration to say that handle-based models serve as the foundation for many, if not all, IDEs built over Eclipse Platform. For example, Eclipse C/C++ Development Tooling (CDT) includes a handle-based model for C/C++ that plays the same role as the Java model in JDT.
Before Handly, Eclipse did not offer any specialized libraries for building handle-based language models. The models that are available now were built mostly by direct adaptation of Java model’s code (a.k.a copy/paste), but only in projects where Eclipse Public License (EPL) allowed that. Obviously, this is not an issue for Eclipse projects; however, proprietary projects are a different matter. This method, in addition to its lack of consistency, is prone to other common problems, such as code duplication and bugs introduced during the adaptation. Even worse, the resulting models are self-contained entities, which do not use their unification potential. Meanwhile, definition of common concepts and protocols for handle-based language models could result in the development of reusable components for integration with these models, just like it was done in the case of EMF.
Of course, Eclipse developers were aware of these problems. Back in 2005, , in his summary of CDT prototype development, of a common infrastructure for language models, including handle-based models. However, as often happens, they had no time to implement it due to other high-priority projects. Even these days, factorization of *DT project code in Eclipse is put on the back burner.
The Handly project is aimed at solving tasks that are somewhat similar to those of EMF, but for handle-based models, and especially for language models (i.e. those that describe structure elements of programming languages). Handly was designed to address the following major goals:
- Definition of the major abstractions within the domain of handle-based models
- Reducing the effort required for the implementation of handle-based language models and increasing their quality due to code reuse
- Development of a uniform meta-level API for the resulting models, which opens the way to develop common IDE components that work with handle-based language models
- Flexibility and scalability
- Integration with Xtext (in a separate layer)
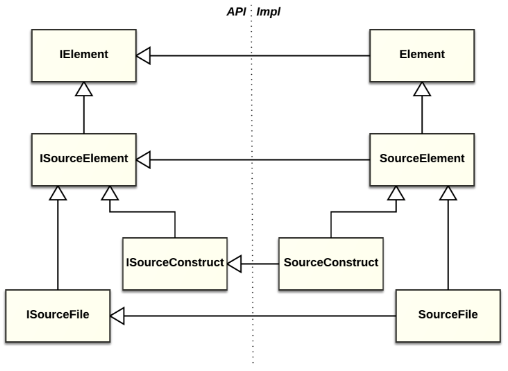
Fig. 8. Main interfaces and base implementations of Handly elements
The IElement interface represents an element handle and is a common interface for all Handly-based model elements. The abstract class Element implements a generalized handle/body mechanism (see fig. 9).
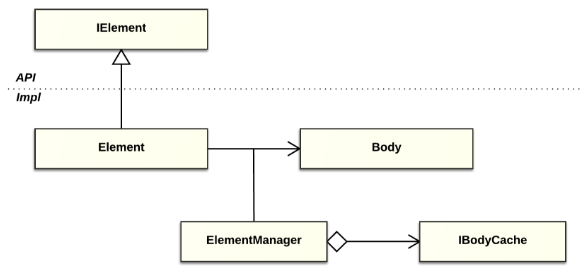
Fig. 9. IElement and generalized handle/body implementation
Besides, Handly provides a generalized facility for notifications about the changes of model elements (see fig. 10). As you can see, it is largely similar to notification mechanisms implemented in the resource model and in the Java model, and it uses IElementDelta for the uniform representation of element changes.
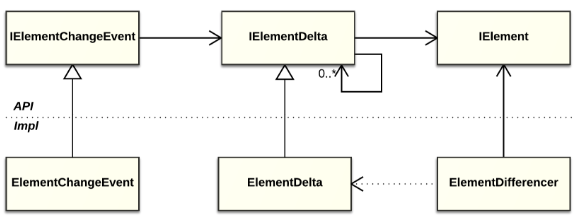
Fig. 10. Common interfaces and base implementations of the notification facility in Handly
The part of Handly described above (see fig. 9 and fig. 10) is suitable for describing virtually any handle-based model. For language model development, the project provides additional functionality, namely common interfaces and base implementations for source text structure elements (the so-called source elements, see fig. 8 ). The ISourceFile interface represents a source file; the ISourceConstruct interface represents an element inside a source file. Abstract classes SourceFile and SourceConstruct implement generalized operations on source files and their elements, such as text buffer operations, binding to element position in the source text, and reconciling a model with the current content of working copy buffer. The implementation of these facilities is not a trivial task, and Handly can significantly reduce the model implementation effort due to the provided high-quality base implementations.
In addition to the main components described above, Handly provides the infrastructure for text buffers and snapshots, support of integration with source code editors (including the out-of-box integration with the Xtext editor), and some common UI components that can support Handly-based models, such as an outline framework. The project offers several demo examples, including a Handly-based implementation of the Java model. (Note that this implementation is intentionally simplified for clarity, compared to the full implementation of this model in JDT.)
As we mentioned before, since the beginning of Handly development we paid significant attention to scalability and flexibility, and we are still committed to this.
In general, handle-based models have decent scalability by design. For example, the handle/body idiom can limit the amount of memory used by the model; however, several fine points must be considered. For example, during the scalability testing of Handly we found an issue in the implementation of the notification mechanism: in scenarios with many changed elements, building the delta took too much time. We found that this issue is also present in the JDT Java model, which we used as a basis for our development. We fixed the issue in Handly and offered a patch for JDT, which was gladly accepted. It is just one of many examples showing the advantage of the integration of Handly into existing models (because this would limit the scope of required fixes to one place).
To make the integration of Handly to existing model implementations possible, the library must provide significant flexibility. The major problem here is preserving backward compatibility with the model API. This task was solved in by distinct separation of model-specific API, which is defined and fully controlled by a developer, from uniform meta-level API provided by the library. This not only allows the integration of Handly to existing models but also gives enough freedom in API design to developers of new models.
Flexibility also has other aspects. For example, Handly sets very few limitations for the model structure and therefore can be used for modeling both general-purpose languages and domain-specific languages. Handly does not require to use any specific AST representation for building the source file structure. It does not even require to use an AST at all, which ensures compatibility with virtually any parser. Finally, Handly supports fully-featured integration with Eclipse workspace but is also capable of working with file systems directly due to integration with (EFS).
The latest version of ) was released in December, 2016. Despite the fact that the project is still in the incubation phase and the API is not yet finalized, Handly is currently used in two large-scale commercial projects whose developers took on the role of early adopters (and they do not regret this so far).
As we mentioned earlier, one of these projects is 1C:Enterprise Development Tools. Since the very beginning, it uses Handly for modeling high-level structure elements of 1C:Enterprise script and 1C:Enterprise query language. The other project is less known to a wide audience. It is , an integrated environment for designing application-specific instruction-set processors (ASIP), which is used both inside Czech company Codasip and outside the company by its customers, including AMD, Mobileye, and Sigma Designs. Codasip uses Handly in production since 2015 (since Handly version 0.2). The latest release of Codasip Studio uses Handly 0.5 released in June 2016. Ondřej Ilčík, the head of IDE development in Codasip, is always in touch with Handly developers and provides valuable feedback as a third-party adopter. He even found time for participating in Handly development and personally implemented the UI layer (~ 4000 lines of code) for the Java model (one of the demos included in Handly). For the first-person view of Handly adoption, please visit the project page.
We hope that with the release of version 1.0 with stable API and the end of the incubation phase, Handly will acquire more adopters. Meanwhile, we test and improve the API and provide two releases each year: one in June (together with a new Eclipse release) and the other one in December. The adopters can rely on this schedule. It is also worth noting that the "bug rate" of the project always remains low and since the very first versions Handly has proved itself as a reliable tool to our early adopters. For more information about Eclipse Handly, please see and .

Writen by


