How to Use Machine Learning in 1C Solutions

Contents
1. Where to focus efforts when applying machine learning technologies?
2. Are 1C solutions ready for artificial intelligence?
3. So, what was accomplished in 1C:CRM?
4. Why create assistants instead of complete automation?
5. How does it work in general?
6. Which technologies were used?
7. How was the communication classification model created?
8. How was the data collected?
9. How was the data processed?
10. How was the vectorization performed?
11. How to choose the machine learning model?
12. How to evaluate the accuracy of the machine learning model?
13. What is the takeaway?
Where to focus efforts when applying machine learning technologies?
First and foremost, you should focus on the area that will help you to improve the quality of automation. Generally speaking, quality means satisfying requirements. Consequently, machine learning will improve quality where traditional algorithms are unable to meet your requirements.Developers of traditional automation systems create algorithms to tackle business problems. In machine learning, solutions are not based on clear algorithms, but on the natural dependencies that exist in the original data. The goal of the developer here is to create a data model that best reproduces these dependencies in order to solve business problems.
First of all, machine learning is focused on patterned, repetitive situations, so it is well suited for cases where you need to automate or control a routine.
In the simplest case, it can auto-complete a cost item based on the precedent of a particular value that was previously entered in an enterprise accounting system document, for example. Another example is when you need to catch errors in a large workflow, that is, you need to identify deviations from some predefined pattern. In this case, machine learning can speed up how fast you can respond to errors and abnormal situations.
Machine learning technologies provide many opportunities that, if applied correctly, can help you to improve the quality of automation of your company's operations. And the question arises about how these capabilities can be used in conjunction with 1C solutions.
Are 1C solutions ready for artificial intelligence?
In order to understand whether your 1C solutions are ready to take advantage of artificial intelligence, you need to answer at least three questions.
The first question is: does your business need such a solution? Of course, all businesses want to increase their profits, including by reducing costs. Therefore, businesses will be naturally interested in any technology that allows them to save money.
The second question is: are 1С technologies ready? Here we should immediately point out that 1C has great integration capabilities. Therefore, the natural path here is close integration with an external system.
The third question is: can 1C solutions generate enough data? 1C does not disappoint in this area either. 1C software is used to automate large businesses, which accumulate data very quickly. Therefore, we can confidently say that the software is ready to provide enough data for machine learning.
In fact, we can point to examples where machine learning has already been put to use in 1C solutions. These examples include recognizing accounting documents, automatically inserting company information in databases, generating hints when filling out forms, and predicting all kinds of indicators. And that is not an exhaustive list of all the existing specific applications. Next, we will take a closer look at an example of how we can create intelligent assistants in the 1C:CRM program.
So, what was accomplished in 1C:CRM?
We have used machine learning to create three intelligent assistants for:- Classifying communications
- Selecting solutions from the knowledge base
- Predicting the likelihood that a client will conclude a deal
Why create assistants instead of complete automation?
We are not trying to replace humans with machines. Our goal is to increase the speed and usability of the software, thereby reducing the number of routines. Here is an example of a hint provided by the inbound communication classification assistant.

We have set a prediction confidence threshold for the program assistant. If this threshold is exceeded, the assistant will not only inform you about its prediction, but it will also go ahead and perform the action to help the user. And we have also set an ignorance threshold, below which the assistant will tactfully remain silent. In all other cases, the assistant will simply share its advice. However, it will not take any action on its own because it is not sufficiently confident.
How does it work in general?
It works really simply. First of all, the user opens a form in 1C. Then control is transferred to the server code, which will send the JSON to the HTTP server after receiving data from the database and performing the required validations. Once the HTTP server, in turn, has received the data, it checks if everything is in order, and it asks the machine learning model code for the prediction. Then the model returns the prediction along with an assessment of its confidence in it, and the data flows in the opposite direction. That is, the data is encoded in JSON, sent to the 1C server side, decoded there, validated, and finally entered as a hint in the form.

According to this schema, there is a potential bottleneck where data is transferred from the 1C server to the HTTP server and back. When you are implementing any tight integration between two systems, the timing of the data transfer between them is critical. Moreover, it is a critical situation for us when the user expects a reply in real time.
These bottlenecks, of course, need to be monitored, and infrastructure must be set up so that they are not felt. In addition, in order to reduce the dependence on this bottleneck, the program allows you to configure a response timeout. If no reply is received within a specified period of time, we consider that there is no reply. The user simply does not receive any hints, like the assistant does not know the answer. However, the user’s work is not interrupted.
Which technologies were used?
We used the following to create the assistants:- The 1С:Enterprise platform and the 1C:CRM industry solution.
- IDE PyCharm. This is the environment that was used for development. This is a great IDE for Python development, and it is incredibly user-friendly.
- Jupyter notebooks. They were used in addition to PyCharm, and they were great for helping with the research and experimentation.
- NLTK library. It contains a number of tools for processing natural language data, and it also proved to be very handy.
- Stanza library. This tool allowed us to perform advanced text processing and deep cleaning.
- Scikit-learn. This is a huge library of simple machine learning models and methods.
- Matplotlib visualization library. You can use this library to build all kinds of graphs, charts, and histograms.
Please note that all of these tools, with the exception of 1C itself, are free. PyCharm has both free and paid versions, and it turned out that the free features provided everything we needed. And one more thing. With the exception of 1C, everything uses the same programming language: Python. Today, the Python language is the standard for machine learning. Just about everything that you need is written in it.
How was the communication classification model created?
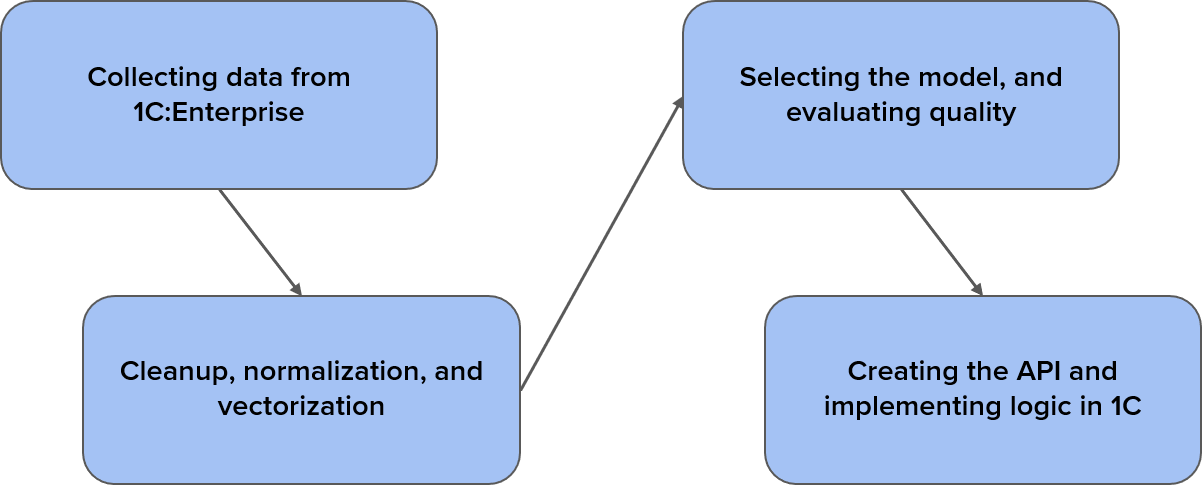
Let's take a closer look at the stages that were used to create the communication classification model.First, we need to collect the input data. We need as much data as possible, and it should not contain any noise. By noise we mean various kinds of boilerplate emails, notifications, newsletters, and so on. We want to filter everything out except for emails written in natural language. As a result, our sample consisted of about 40,000 emails.
Then we need to clean all of the noise out of the collected data as best as possible. However, we should not overdo it. We need to keep as many of the natural dependencies intact as possible. It’s a rather complex task. We need to convert textual data into numeric data, that is, to encode the data. This procedure is called vectorization.
After that, we choose the model that is best for describing this data. There are a large number of ready-made models of varying complexity that are suitable for various tasks and for different data. Here, simpler does not mean inferior. And if, say, simple logistic regression is good enough for training based on your data, then there is no point in using a neural network.
And finally, the last stage is to create an application that will function not based on programmed logic, but on your data. Of course, we need an API here and a certain client. When it comes to setting up a client, the latest capabilities of the 1C platform can help out a lot with creating extensions and designing the interface.
How was the data collected?
Our classification task was interested in three types of emails. The first is e-mails with commercial promise, so-called leads. The second includes emails requesting consultations. The third are emails with client complaints.Our accounting system in 1C:Enterprise tells us what each email contains. Our task was to train a model for classifying communications based on texts and labels that we assigned to each email.
How was the data processed?
Before we delve into the details of data processing, first let’s get the terminology straight.- A corpus is a collection of texts to be analyzed.
- A token is a unit of textual analysis.
- A stem is the root of a word.
- A lemma is the dictionary form of the word.
- A POS label is used to indicate part of speech.
A token is most often simply a word. When collecting and processing data, we need to break the text down into sentences and the sentences into words, that is, we need to tokenize it. This is a rather non-trivial process, and we were able to achieve it using the NLTK library, which includes simple methods based on regular expressions. The words obtained in this way must be reduced to their basic forms, since the same word in Russian can have many different morphological forms.
To obtain the basic form of words, we need either to use stemming to obtain the lexical base form or lemmatization to obtain the dictionary form of each word. Stemming tools can be found in the NLTK library, and we used the Stanza library for lemmatization. The difference between these two operations is that stemming is faster. However, it removes a lot of information, and too many different words are reduced to the same base form. By contrast, lemmatization is a more careful process, but it is also much more resource intensive to process data.
Finally, there are POS labels. They are used to mark the parts of speech for the obtained words. This, for example, will allow us to throw out all of the proper names, meaning the names of persons, from our email corpus. Unless, of course, we want to train our model on the basis of these personal names.
So now that we got the terminology straight, let's describe the main stages of data collection and processing.
First, we assemble a labeled corpus and save it to disk. Then we use tools for stream reading, tokenization, and marking up the parts of speech. We throw a lot away during processing. For example, auxiliary parts of speech, personal names, names of cities and software products, web links, and e-mail addresses. We will use the material that remains for our analysis. After this processing, the document must be saved to disk again, after which we are ready to work with our processed corpus.
We can then also start analyzing the processed data. For example, we can get an idea about the statistical breakdown of the words in the corpus.

We can also try simple clustering algorithms to see how easily the data can be grouped into clusters. The figure shows that simple methods may poorly group data, which is the case in most real-world tasks.
How was the vectorization performed?
Data must first be quantified before it can be transmitted to the model. And this is where frequency encoding comes to our rescue.Frequency encoding works like this. First, the program compiles a dictionary for the entire corpus. Then, each document is represented as a vector containing the frequencies of occurrence of all words in the dictionary. The vector will be very long and sparse. In other words, there will be zeros at many positions.
If we recall how much we threw away in the previous steps, we understand that this was in order to reduce the size of the model's feature space. But even after that, the size still remains very large. The entire corpus looks like a large and sparse matrix when represented in this form. It has as many rows as there are documents in the corpus and as many columns as there are words in the dictionary. This type of document representation is called the “bag-of-words” model.

How to choose the machine learning model?
Choosing a model is not an easy task. On the one hand, it is best to keep it as simple as possible. On the other hand, it must be well trained using the data. There are known problems that can only be well solved using complex neural networks, but there also ones for which such a complex approach is not needed. The general principle is to start with the simplest models. You then gradually increase the model complexity until you find a suitable one for your specific data.Every ready-made model that you can use was originally created by someone for a particular purpose, and subsequently it was added to the model library. Articles have been written about it. Perhaps there are even model datasets for which it produces a certain guaranteed result. It is useful to familiarize yourself with all of this.
It is important that each model has its own parameters, and you should try to select the optimal values for them. As a rule, they are rather abstract, so usually you just need to find the optimal values for the parameters. To do this, you can either perform a direct unit-by-unit search over the entire grid of parameters (a kind of brute force method), which consumes a lot of resources, or you can use more optimized algorithms.
There are two important problems with machine learning models. These are underfitting and overfitting.
Underfitting means the model makes poor predictions and is often wrong. This can be caused, for example, by the excessive simplicity of the chosen model. In other words, the model simply did not learn from those natural dependencies that are available in the data.
Overfitting occurs when the model, on the contrary, is too complex, and it has learned not only from dependencies, but also from noise, which it is also impossible to totally clean from the data. In this case, the model generalizes very poorly to data it has not seen before, and it again gives low prediction accuracy.
So, as the complexity of the model increases, the accuracy first increases and then decreases again. You need to look for the golden mean.
How to evaluate the accuracy of the machine learning model?
In order to determine that we chose the correct model, and that it can generally predict something similar to the truth, we use the technique of subdividing the training sample into training and test subsamples.This is how we do this: We strip away some of the training data (for example, a fifth of all the data) and put it aside, and we use the rest of the data to train the model. Then we validate the prediction accuracy based on the data that was set aside and get a quantitative measure of accuracy. It displays the share of correct answers out of the total number of replies. This is called validation based on a test set. We train using a training set and validate using a test set.
But it would be a pity not to use some of the data that we have obtained with so much effort in order to train the model. Therefore, there is a modification of the validation method for a test set, which is called cross-validation. This is what is done here. The training sample is divided into 5 parts. Four of them are used to train the model, and the fifth one is used for validation. Then the parts are swapped and the average accuracy is calculated.
In addition to the advantage of being able to use all of data for training, this allows us to handle the problem of overfitting. If the quality decreases when cross-validation is performed, then, most likely, the model has been overfitted.
In addition to accuracy, there are many other metrics that, depending on the situation, are better able to demonstrate the quality of the model. For example, when the amount of data corresponding to each label differs greatly. This is what is called class imbalance.

What is the takeaway?
Today, machine learning technologies are mature enough to allow you to quickly develop and implement solutions using them.Preparing data and selecting a model is a rather complex but exciting process that requires accurate knowledge, an understanding of the situation, and creativity.
There are a number of ready-made machine learning models that are available to use now. You should find out through experimentation which one is best for your situation.
1C solutions have good potential to be supplemented with machine learning capabilities. We believe that the time has come to apply machine learning to the field of business automation on the 1C:Enterprise platform. And we can hope that both 1C and machine learning will only benefit from this collaboration.



