The Way We Handle Data Models in 1C Enterprise or “Why Avoid Tables?”

With this article I would like to describe a data model we utilize in 1C Enterprise and explain why.
When we talk about business applications, it is essential to decide how we want to handle data because this determines the architecture of the software. One way or another, every application is built around data. And while in some software data plays an auxiliary role, in business applications it is the core. This article does not touch upon technical aspects of data storage and handling but focuses on how data representation impacts application design.
Why is data so important for business applications?
The reason is that we use data to describe a subject matter. We need to know entities relevant to a particular business and how they relate to each other. Data serves this purpose very well. Still, in the process of designing an application, we are not trying to include all data possible. Instead, we need task-related entities with their relations, plus some reserve to ease future development in directions that have good potential. Imagine we want to automate the staff development process. In this case, we collect data on personnel education and employment history. At that, data on shoes and clothes size is of no interest to us.
On the other hand, if we aim to automate workwear management, this becomes relevant. I assume that a curious mind might wish to go even further. Just think about the following. Where there is staff development, there is a place for motivation. Motivation brings in corporate workwear, and so on. As you can see, data is practically limitless, and the art of application design has a very close connection with the art of data modeling.
Still, it is no doubt that processes play a significant role in business applications. Like other developers of business application platforms, we believe that they significantly impact application design. Nevertheless, we should not underestimate the importance of data. It is the approach to the presentation of data that determines how an application will work.
At that, I need to mention that by data we mean actual data plus associated processes. Thus, processes, though indirectly, are still present in the data model.
1C:Enterprise platform offers tools to work with processes directly, but this is a subject for another article.
There are several approaches to data processing.
To begin with, it is a classic relational model. Data is presented in relational tables (usually stored in a relational database management system). This approach is far from being new but remains relevant.
Another approach is object-oriented programming. Data is treated as a programming language object and is stored in a database. It can be either a relation or an object-oriented one. In the first case, modeling is governed by DBMS, while in the latter, ORM comes into place.
In addition to these two approaches, developers utilize some other methods and solutions when designing business applications. Semi-structured data approach is among them.
Now we are gradually getting to the approach we have chosen for the 1C:Enterprise platform. It has no universally recognized name, and we decided to call it the applied object type model. The key concept is that the platform contains many applied object types. These object types describe specific categories of subject-related entities within an application model. Designers describe a data model picking appropriate object types. By doing so, they present not only the data model but mostly the application model itself. We will get back to this part a bit later.
So what is meant by applied object types?
You can treat it as a preprogrammed template (or an abstract class) that defines multiple aspects of how the platform handles subject-related entities. Applied object types are used both during design-time and run-time. In design time, this is either a meta-model to describe objects through metadata or entity classes to handle data within a program model. In run-time, these are the rules that determine how the system handles objects. Consider a lock engine mechanism. It is an excellent example of the case.
In 1C:Enterprise, we use several applied object types.
Let’s take a closer look at three of them:
- Catalogs
- Documents
- Accumulation Registers
Catalogs store static content (lists of employees, goods, and clients).
Documents contain events relating to particular subject matters (sale, admission to job, bank transfer, and so on). Sometimes they have names of print forms like Payment Order or New Hire Form. But this is just for the sake of convenience. In fact, this is an event type and not a print form.
Accumulation registers serve for the keeping of records, like cash assets accounting or warehouse inventory.
Now we can have a closer look at the set of features offered by applied object types.
Applied object types describe a data model, thus placing data within a relational model. But this is just a smaller part of a bigger picture.
With catalogs we can:
- apply standard attributes (fields) built into the platform (reference ID, code, description, link to parent in hierarchical catalogs, etc.)
- add our own (optional) attributes (fields)
- describe tables treated as containments (also called nested tables).
Documents are about the same, but here we have Date as a standard attribute that places an event on a timeline and Posted flag to show whether a document is registered in the system or remains in draft state.
Accumulation registers have such fields as dimensions, resources, and attributes. Dimensions describe an accounting model type (like goods, warehouses, etc.). Resources are values used within a particular register(number of products or cash amount. Attributes are optional fields for comments and have no impact on the model.
So why do we use applied object types instead of tables or even entities?
It is a good question. Tables offer plenty of advantages. They are a better fit for simple relational models and do not suffer from limitations imposed by predefined types. On the other hand, tables lack features granted by our platform.
The key benefit of our approach is that the platform so to say “knows a lot” about objects and “can do a lot to them.” With this knowledge and ability at hand, the system automatically engages dozens of mechanisms that work with objects both directly or indirectly. As soon as developers pick an object type and describe the object, the system can instantly use this information to initiate plenty of valuable tools and mechanisms. The idea behind it is that we define general semantics on the level of an object type and then specify a particular object semantics by means of metadata via properties and designated models describing various aspects.
These are some mechanisms you can find within the platform.
- Keeping of data as structures and automatic transformation of these structures on data model change.
- Handling data (like reading, writing, searching) through object model classes.
- Object-relational mapping
- Utilization of standard data processing procedures, like automated numbering for documents, calculation of register totals and balance as of specific date and time, and so on.
- Role-based access control. As the system knows each object’s designation, it can assign applicable rights and permissions.
- Visualization (interface). Again, as the system knows each object’s rights and designation, it automatically creates menu items to access required object types, as well as forms to view and edit them and commands to allow interaction.
- Data exchange. The platform uses data semantics to asynchronously distribute modified data between both single vendor applications (distributed infobase nodes) and multivendor ones (built either on 1C:Enterprise or other technologies).
- Object and transaction locks. To properly set up an interlock system, you need to know how data is to be used and how it relates to other pieces of data.
- Characteristics. These are additional fields users can introduce if needed.
- Automatically generated REST interface (per OData standard)
- Data import and export in XML and JSON formats
- In addition to the abovementioned functionality, full-text search, data access logging, and similar mechanisms are available at all times and require no additional setup.
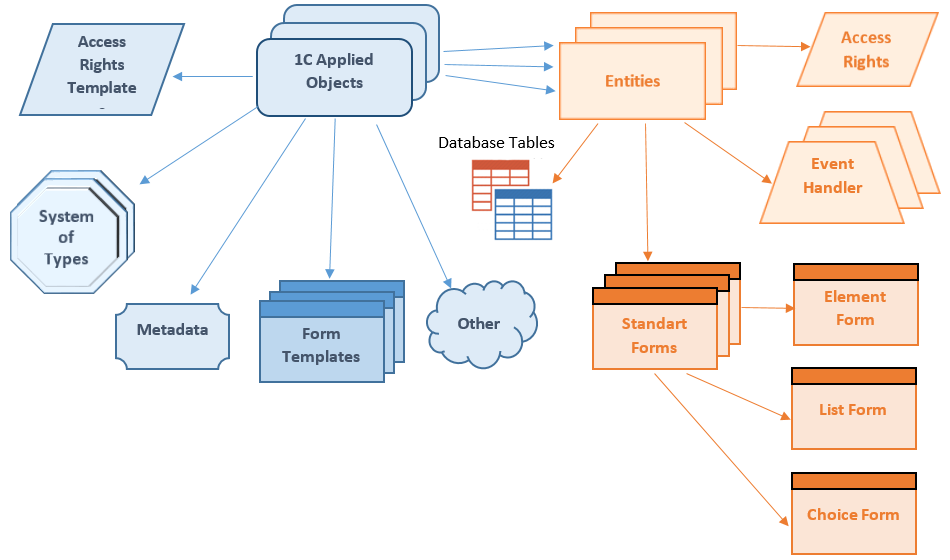
These are just some platform mechanisms relying on applied objects.
To some extent, the approach resting on applied object types is equal to an aspect-oriented one. All features listed above are predefined aspects described as applied object types. But applied object types are not simple templates. Instead, they are more like parameterized ones, where parameters are defined with metadata. By selecting values in properties, developers adjust a template, thus defining how an object will act within specified conditions. Here is an example. To have the system automatically assign and control document numbers for a specific period (year, quarter, or month), you need to set up a document numbering period.
Applied object types contain data on the semantics of both entities and their interrelations. An excellent illustration is a standard connection between documents and registers determining how events are presented within an accounting model. With this connection established, the system immediately creates a relationship between a document and relevant records in the register. At that, the records remain in the system as long as the document exists.
Also, I believe it is good to mention some useful subject-related aspects.
For instance, you can enable hierarchy mode in catalogs with a single flag. It will allow support for hierarchy catalogs everywhere, including user interface, reports, and object model.

Enabling “Hierarchical catalog” in catalog properties allows hierarchy catalogs everywhere, including user interface, reports, and object model.
Within Documents, you can consolidate several document types in a journal or apply continuous numbering within a period.
In Accumulation registers, the most important feature is an automatic saving of calculated results and ready-to-use virtual tables to evaluate results per specific period.
To put it simply, applied object types contain a majority of universal (standard) mechanisms that can be used to implement business logic in end-user applications.
As a result, developers use object types as Lego parts to build applications of their own. Apart from other solutions that contain “abstract” elements, we offer “parts” with a specific purpose in mind like “wheels,” “windows,” or “doors.”
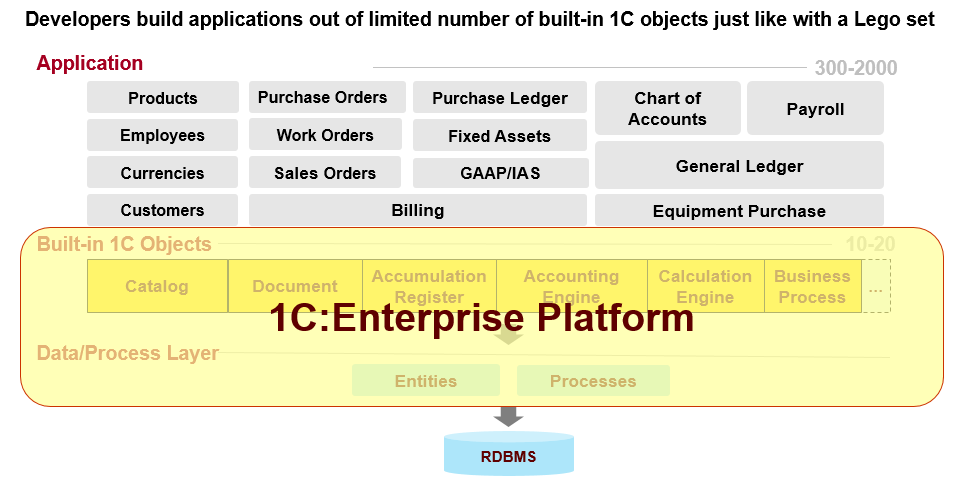
Developers need catalog type to create goods, employees, currencies, and client catalogs. They use document type to create purchase orders, invoices, and sales orders.
So why do we think this approach is right methodology-wise? All developers share a common set of concepts that help them better understand the nature of applications and simplify communication between each other. Even being new to a 1C:Enterprise project developers can immediately see familiar elements and quickly identify the role of objects within a system. Here is a good example. Registers used within an application clearly describe what the application is built for. With applications based on tables and classes, it is much more challenging to get the idea by simply looking at such structures.
But more important is that such an approach pulls together the language of developers and business people (or analysts). The importance of a language that both parties can equally understand is well described in Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans. Applied object types are easy to understand for non-developers, making it easy for analysts, customers, and developers to discuss project functionality. It is pretty common to have business persons or analysts with no experience in software development but capable of describing the task with 1C:Enterprise applied object types.
What else to say? Such an approach stipulates the ongoing evolution of the system. We add new mechanisms to the platform. They are immediately ready to interact with existing objects (with no or minimum efforts on behalf of developers). Some time ago, we introduced data changes history (or versioning) functionality. As our system relies on data semantics concept, developers can simply enable history of changes for a specific object by flagging the option, and the system takes care of everything, starting with storing of changes to visualization of such changes in various reports. When we had introduced the standard REST interface (per OData standard) sometime before, all applications immediately received a ready-to-use REST interface without any effort on behalf of developers.
So why don’t we complement our applied object types with common tables? Well, it is a good question. And we are still looking for the answer.
It looks tempting on the one hand. Seems to be a good solution for cases where subjects do not ideally fit into predefined applied object types. How much easier it would be with developers! We could say, “Here is your simple table. Do whatever you think fit.” But on the other hand, this will leave our standard mechanisms clueless. How do they pick a proper way to process data with no data semantics included? Though, to some extent, you can do it like this even now. Technically, we apply it to external sources. But in this case, we stay limited to simple tables that contain no information on a subject. The system can process them, but some functionality is lost.
Thus, for now, our decision is to avoid simple tables to retain the platform integrity and remain capable of adding new functionality requiring data semantics. If existing features are insufficient to meet our needs, we will first seek to improve applied object types. Naturally, this is not a final decision, and we might reconsider it in the foreseeable future.
To crown it all, it is worth saying that applied object types are the foundation for platform features and the cause of the high level of abstraction that developers enjoy so much. This is precisely what makes 1C:Enterprise so different from other development environments, and this is one of the major keys to quick and unified software development.



