Working with Diverse DBMSs in 1C: How We Do It Without Losing Our Minds (or Calling the Developers)

Working with Diverse DBMSs in 1C: How We Do It Without Losing Our Minds (or Calling the Developers)
Everyone knows that the more DBMSs and operating systems a program supports, the better. More users, more fun, right? But let's be real: each new DBMS also means more headaches (and more work for our developers, bless their souls). That's why we're always looking for ways to make our lives easier. And by "easier," we mean figuring out how to support as many databases as possible without adding a single gray hair to our developers' heads.
This article reveals the secrets behind our technology platform, a magical creation that can manage various DBMSs without breaking a sweat (or requiring any changes to the business application code). Think of it as a universal translator for databases.
Curious about how we handle different operating systems, browsers, and those troublesome mobile operating systems? We've got you covered! Check out our other articles for all the juicy details: here, here and here

1C:Enterprise Platform: A Crash Course for the Uninitiated
Picture this: a world where developers can create business applications at lightning speed. That's the 1C:Enterprise platform in a nutshell. But we didn't stop there. Oh no, we wanted to make our developers' lives as stress-free as possible. So, we designed the platform with a simple philosophy: let the developers focus on what they do best: building amazing applications.
No need to get bogged down in the nitty-gritty of operating systems or the quirks of different DBMSs. That's our job, and we're happy to take one for the team (especially if it means fewer panicked calls from developers at 3 AM). Here is the link for those who want to know a little more.
In the 1C:Enterprise world, developers (or as we like to call them, application developers, gotta love those fancy titles) work their magic on application objects like catalogs, documents, and charts of accounts. Think of these objects as the building blocks of their creations. We handle the whole "storing data in a database" thing behind the scenes, like a well-oiled machine (most of the time, anyway). Want to dive deeper into our data model and why we chose this approach? We wrote an entire article about it! It's called
The Way We Handle Data Models in 1C Enterprise or Why Avoid Tables . Yes, we like to name things.
Of course, data integrity and consistency are non-negotiable. With developers scattered across different operating systems and clients potentially using their own unique DBMSs, we need to ensure everything plays nicely together. Think of it as a giant database party, and everyone's invited.
The above-mentioned application developer creates objects within the application (or "configuration," in 1C:Enterprise terminology):
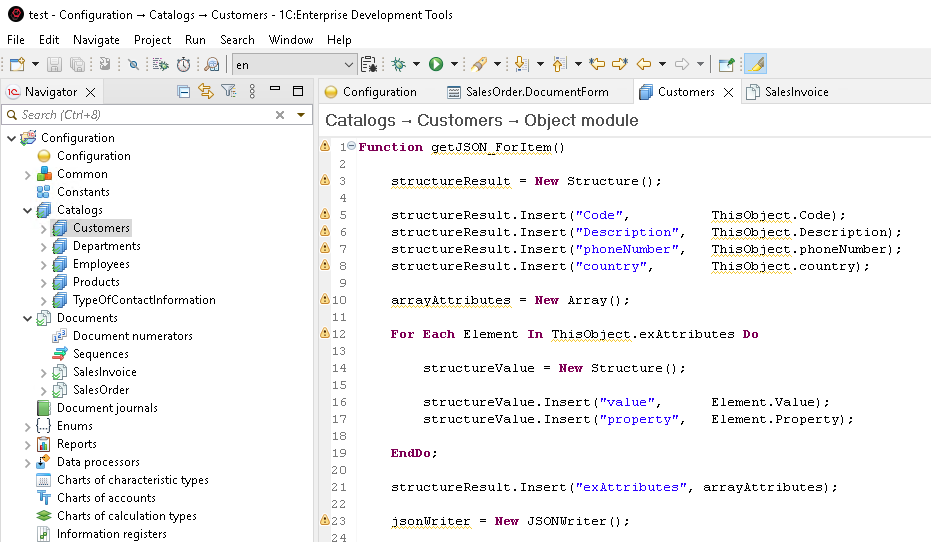
For many types of application objects, you can add attributes to store their properties (kind of like giving them a personality profile). These attributes reflect the characteristics of their real-world counterparts, such as a product's name. (Think of it as giving a digital product a name tag.) In the world of object-oriented programming, these attributes are basically the equivalent of fields or class properties
And the best part? The platform automatically creates tables for these objects and connects them with invisible threads of logic. This magical process is hidden from our developers, sparing them from existential database crises. They can merrily build their configurations in one DBMS, knowing that the platform will handle the heavy lifting of making it all work in other DBMSs.
It's a win-win: our developers stay sane, and the 1C:Enterprise platform gets to show off its versatility.
The 1C:Enterprise DBMS Party: Who's Invited?

Our platform is a welcoming host, embracing four of the most popular industrial DBMSs:
-
Microsoft SQL Server
-
PostgreSQL
-
Oracle Database
-
IBM DB2
But wait, there's more! We also have our own file database format, perfect for smaller gatherings.
And for those who demand lightning-fast performance, we offer the Data Accelerator, an in-memory DBMS that stores data in RAM. Think of it as the VIP section of our database party, where everything runs at warp speed.
Need to access a DBMS that's not on the guest list? No problem! Our external data source mechanism can connect to any ODBC-compliant DBMS.
Let's illustrate this with an example. We need to implement a Product entity in the application, along with a subordinate one-to-many Additional Attributes entity. We also want to be able to work with a list of products.
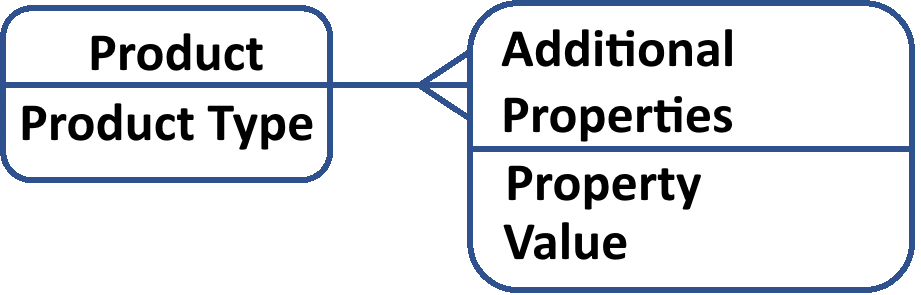
Our trusty application developer decides to tackle this challenge with the catalog application object, a natural choice for storing structured data that loves to make lists (who doesn't love a good list?). Catalogs also allow storing information for each element in a structured yet flexible way, thanks to their trusty companions, tabular sections.
With the plan in place, our developer creates a Products catalog and with an AdditionalProperties tabular section.

But here's where things get interesting. If we load this configuration onto different DBMSs, we encounter some naming discrepancies. For instance, MS SQL and PostgreSQL prefer to start their column names with an underscore (_), like they're whispering a secret code.

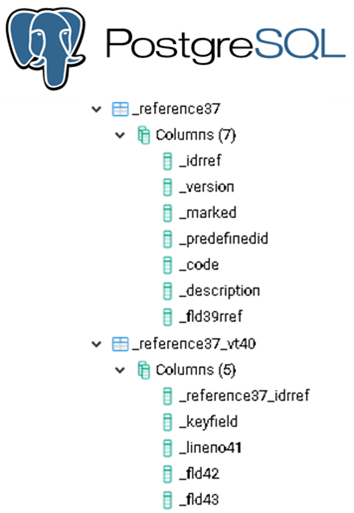
Oracle Database, being the independent soul it is, marches to its own beat with its unique naming conventions.
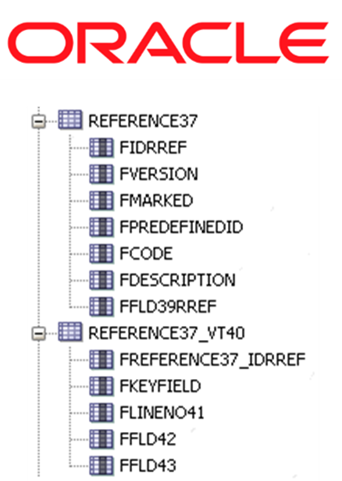
And then there's IBM DB2, which takes things to a whole new level. Not only does it add a U postfix to each text field (we suspect it has a thing for uppercase letters), but it also prefers to use aliases instead of directly addressing tables. It's like having a secret handshake for databases.
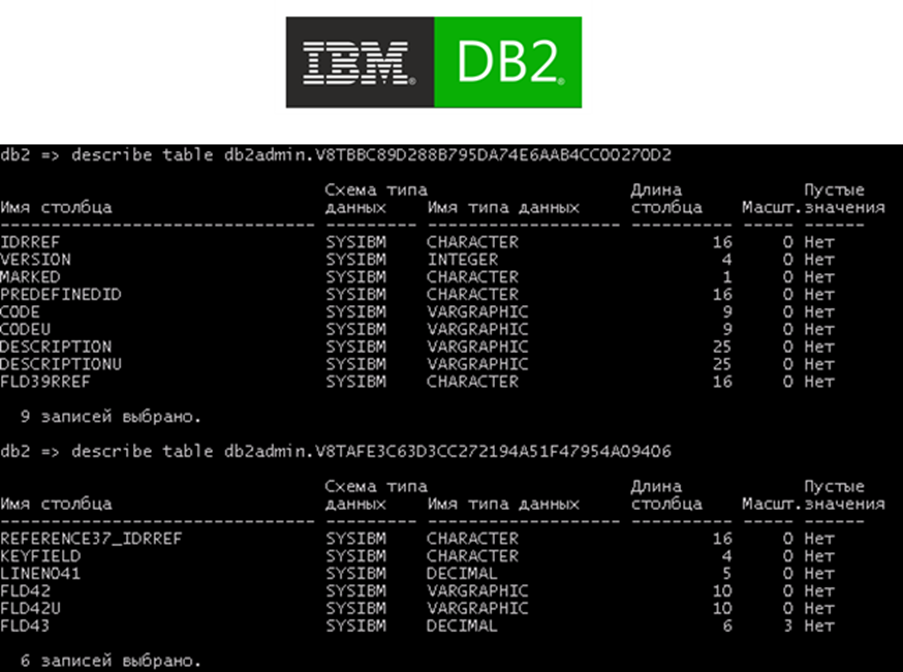
Don't worry, our developers don't need to memorize all these quirks. The 1C:Enterprise platform handles this complexity behind the scenes. It's like having a dedicated team of database whisperers working tirelessly to ensure a seamless experience for our developers.
While other frameworks might offer similar features, 1C:Enterprise stands out by enabling seamless application portability across different DBMSs without requiring developers to lift a finger (or modify a single line of code). It's like magic, but with less glitter and more ones and zeros.
To ORM or Not to ORM: That is the Question
"Hold on!" you might say. "What about object-relational mapping (ORM)? Isn't that the solution to all our database woes?"
And you wouldn't be wrong. ORM is a powerful tool that allows developers to work with classes instead of wrestling with database tables directly. It's like having a personal translator for communicating with the database, speaking fluent SQL and everything.
There are countless ORM implementations out there, especially for Java. Hibernate, EclipseLink, Open JPA, you name it... No matter your preference, there's an ORM for that.
Imagine implementing our trusty product catalog using Hibernate. We'd have Product and Table 1 Row objects, each neatly mapped to its own table. Annotations would handle the table naming and field-to-column mapping, while relationships between classes would gracefully translate into table relationships. It's like a match made in database heaven.
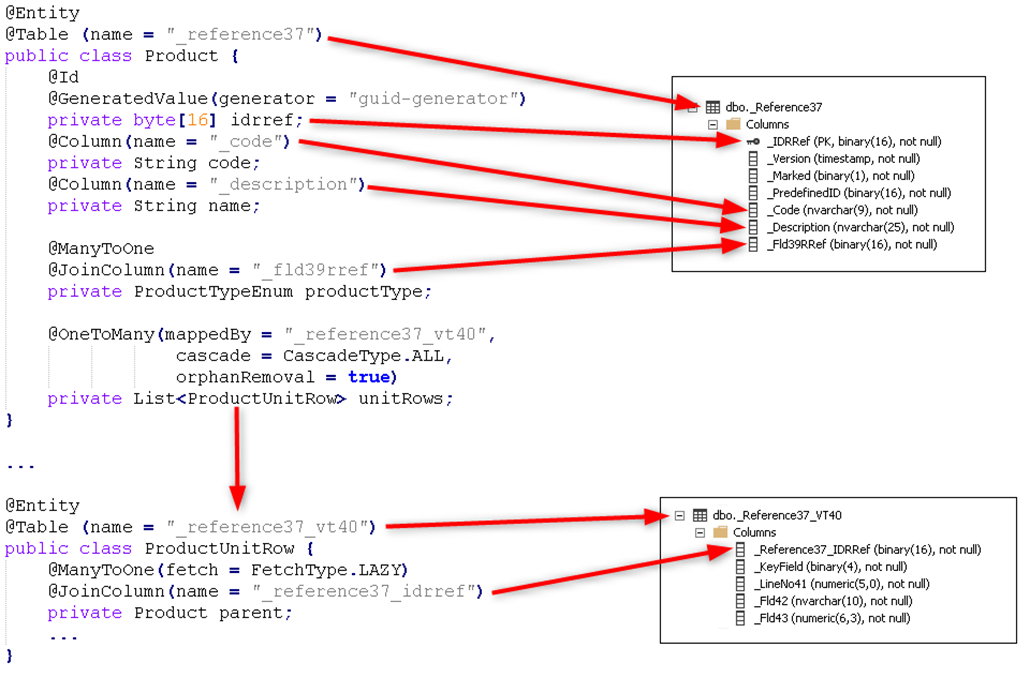
But alas, traditional ORM and 1C:Enterprise are not meant to be. You see, ORM is typically compiled alongside the application code, while we do things a bit differently. Our configurations are developed using 1C:Enterprise language, a language that ORM doesn't quite understand. It's like trying to explain Shakespeare to a toddler: well-intentioned, but ultimately useless.
Even though many ORMs boast multi-DBMS support, achieving true DBMS neutrality is a Herculean task. Most ORM query languages end up being translated directly to SQL, with minimal consideration for dialect variations. This means that DBMS-specific features can "leak" through.
And let's not forget that 1C application developers are a resourceful bunch. They often prefer to write their own SQL-like queries, like crafting their own secret database language.

So, while ORM is a fantastic tool in the right context, it's not the silver bullet for our unique set of challenges. We needed a custom solution, something tailored to the quirks of 1C:Enterprise, a solution that would make our developers rejoice and strike fear into the hearts of incompatible databases.
Introducing SDBL: The Language That Tames the Database Beast
Sometimes, one object property decides it needs not one but two database fields to truly express itself. And then there are those rebellious objects that insist on being represented by multiple tables, like they haven't heard of minimalism.
For instance, there's an application object called accumulation register a crucial component for tracking the movement of resources like finances, goods, and materials. This multitalented object is a master of warehouse management, accounting, and planning.
Accumulation registers store their precious information as records. Each record is like a treasure chest, containing dimension and resource values. Dimensions are the labels on the treasure chest, telling you what kind of treasure lies within, while resources are the actual loot (the numerical data we crave). Of course, no treasure chest is complete without a date stamp, automatically added by the platform (but customizable if you're feeling adventurous).
Let's take inventory tracking as an example. An inventory accumulation register might have a Products dimension and a Quantity resource. But wait, what if we want to know the quantity of each product in different warehouses? Fear not! We can simply add a Warehouse dimension, giving us a multi-dimensional view of our inventory.
The best part? Accumulation registers can calculate totals for specific periods, like magic. This means we can generate reports with lightning speed, impressing our bosses and making it home in time for dinner.
Implementing this marvel of an object involves creating not one but three tables in the database:
1. The Register Record table: This table keeps track of all the comings and goings of our precious resources (like those sneaky goods that always seem to disappear).
2. The Accumulation Register Totals Storage Settings table: This table, with a name that only a developer could love, defines how long we keep track of our totals (because even databases have their limits).
3. The Totals table: This table presents the fruits of our labor, the calculated totals for different periods, ready to be analyzed, scrutinized, and presented in colorful charts.

Now, imagine the chaos if we changed the structure of our configuration, adding a new dimension, renaming a resource, or, heaven forbid, deleting something entirely. Data loss would be a very real possibility, leading to much wailing and gnashing of teeth.
But fear not, dear reader, for we have a solution! We developed a special language specifically for such situations: the Special Database Language, or SDBL for short. This intermediate language acts as a mediator between the 1C:Enterprise platform and the database, ensuring that every interaction is handled with the utmost care and precision.
Every single database interaction, from requests originating from the 1C:Enterprise language to internal service requests within the platform, is channeled through SDBL. It's like having a dedicated translator for database conversations, fluent in all dialects and immune to misunderstandings.
For example, if an application developer dares to request the name and type of a product from the catalog, the platform springs into action, translating this request into SDBL and then into a DBMS-specific query that the database can understand. It's like a perfectly choreographed dance, but with fewer sequins and more data.

Let's crank up the complexity a notch. What happens when a developer wants to create a new object? The platform doesn't break a sweat. It assigns a unique code to the object (after meticulously checking for existing codes, of course) and then gracefully inserts it into the table.

The beauty of SDBL is that it streamlines the entire process. It defines both the object's data and its tabular section, all in one go. A single SDBL query can spawn multiple DBMS queries, like a hydra of database efficiency. First, it inserts data into the product table, then it tackles the unit of measurement table, and finally, it verifies the object version to ensure data consistency. It's a symphony of database operations, conducted with the precision of a Swiss watch.
But SDBL's talents don't end there. Oh no, it's also used in the platform's source code, allowing us to write DBMS-independent code that's as adaptable as a chameleon in a rainbow. All data interactions in our C++ codebase flow through SDBL, ensuring a consistent and harmonious relationship with our database overlords.
Want to assign a new code to an application object? SDBL to the rescue! The platform constructs an SDBL query to find the highest existing code (because every object deserves a unique identifier) and then dispatches it to the DBMS for execution.

Of course, each DBMS has its own unique way of setting a new code, like a signature move. But that's what makes our job so interesting (and occasionally hair-pulling).

While SQL syntax might be the standard language of the database world, each DBMS has its own dialect and quirks. It's like traveling to a foreign country where everyone technically speaks the same language, but with enough regional variations to make you question your sanity.
The more complex the query, the more these nuances come into play, like a mischievous gremlin determined to sabotage our best efforts.
Unpacking SDBL: A Peek Inside the Magic Box
In the realm of SDBL, the package reigns supreme. These packages are like containers, holding one or more SBDL statements that dictate the database's every move. We have two main types of packages:
-
Data Definition Packages: These packages are the architects of the database world, responsible for defining the structure and organization of data. They hold the blueprints for creating, modifying, and deleting database objects, ensuring that everything has its place and purpose.
- Data Manipulation Packages: Once the data architects have done their job, it's time for the data manipulators to work their magic. These packages handle all the actions we perform on our data: retrieving, adding, updating, deleting. You name it, they do it.
Data Definition Package: The Architects of Data
These statements are the building blocks of our database structure:
-
CREATE: This statement brings new objects into existence, like a database version of "let there be light!" With a single command, CREATE breathes life into new objects: tables, indexes, views. Dream it, and CREATE will make it a reality within your database.
-
DROP: When it's time for an object to meet its maker (or at least be removed from the database), DROP is the statement for the job. It's a swift and decisive end, leaving no trace behind.
-
RENAME: Sometimes, even database objects need a makeover. RENAME allows us to give objects a fresh start with a new name, like a database version of witness protection.
-
REMOVE: Think of REMOVE as a gentler version of DROP. It removes an object from the configuration but gives us the option to keep its data, just in case we change our minds (we've all been there).
-
SET_GENERATION, GET_NGENERATIONS, RESTORE: These statements work behind the scenes, ensuring a smooth transition when we update our configurations and change the database structure. They're like the stagehands of the database world, making sure the show goes on without a hitch.
Need to create two catalogs: Organizations and Warehouses?
No problem! We'll whip up an SDBL package with a CREATE statement for each catalog, specifying their structure and indexes. It's like ordering a custom-made database structure, tailored to our exact specifications.
And if we ever need to make changes to the structure, our trusty restructuring mechanism will swoop in, using those handy SET_GENERATION, GET_NGENERATIONS, and RESTORE statements to ensure a seamless transition. We'll dive into the intricacies of restructuring later, but for now, just know that it's our secret weapon against data loss and configuration chaos.

Data Manipulation Package: Where the Action Happens
Once the data architects have set the stage, it's time for the data manipulators to take over. These statements are the verbs of the database world, responsible for all the action:
-
SELECT: The most popular kid on the block, SELECT retrieves data from the database, like a seasoned detective gathering clues. It's the go-to statement for querying data, filtering it, and presenting it in a format that even humans can understand.
-
INSERT: Need to add new data to the database? INSERT is your friend. It takes your precious data and carefully inserts it into the appropriate table, like a skilled surgeon performing a delicate operation.
-
DELETE: When it's time to say goodbye to data (either because it's no longer needed or because it's causing trouble), DELETE swoops in to erase it from existence (or at least from the database).
-
UPDATE: Data, like life, is constantly changing. UPDATE allows us to modify existing data, ensuring our database remains up-to-date and reflects the ever-evolving nature of reality (or at least the data we choose to store).
-
SET, LOCK, UNLOCK, DROP: These statements handle various behind-the-scenes tasks like setting variables, managing concurrent access to data, and cleaning up after ourselves when we're done. They're the unsung heroes of the data manipulation world, ensuring everything runs smoothly and efficiently.

The platform then translates this into a DBMS-specific SQL query, like this one for MS SQL Server:

SDBL: The Master of Translation and Optimization
Every single interaction between the 1C:Enterprise platform and the database goes through a rigorous translation process. First, the request is transformed into an SDBL package, like a secret message being encoded. Then, this package is translated again into the specific SQL dialect spoken by the target DBMS. It's a two-step process that ensures clear communication and prevents database misunderstandings.
But there's more to this translation process than meets the eye. It's not just about converting code from one language to another; it's about optimizing it along the way. The platform acts as a master optimizer, analyzing each SDBL query and fine-tuning it for maximum performance on the target DBMS.
It's like having a personal trainer for your database queries, pushing them to achieve peak performance.
And let's not forget about security. The platform also incorporates access restrictions defined in the configuration through a mechanism called Row-Level Security (RLS). This ensures that only authorized users can access sensitive data, keeping our database Fort Knox secure.
This layered approach makes our lives a whole lot easier when it comes to supporting new DBMSs. Instead of rewriting the entire platform for each new database, we simply create a new translator for that specific SQL dialect. It's like adding a new language to our database repertoire, expanding our communication horizons without breaking a sweat.
But the real beauty of SDBL lies in its ability to optimize queries for any supported DBMS. It's like having a universal optimization engine that can squeeze every ounce of performance out of any database, regardless of its quirks and peculiarities.
Let's look at a real-life example (because who doesn't love a good performance optimization story?). We encountered a scenario where a platform service request for accumulation register balances was exhibiting suboptimal performance on MS SQL. The culprit? A poorly optimized query that relied heavily on the OR statement, making the database work as hard as a car stuck in first gear.
The query and its execution plan on the test database looked like this:
![]()
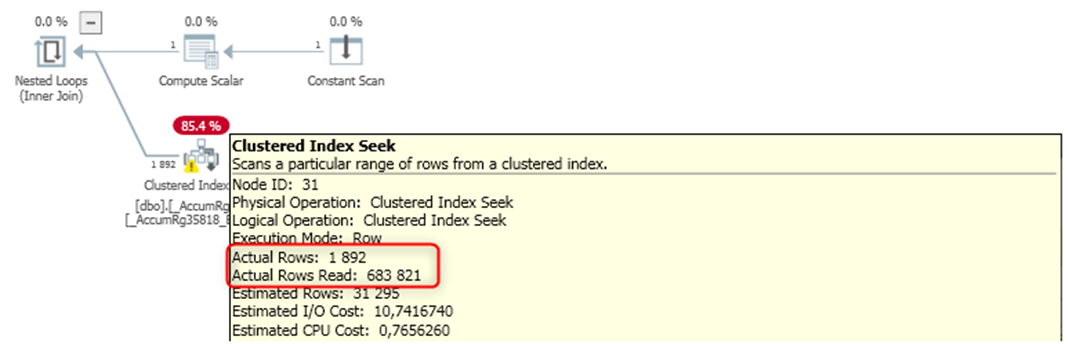
To retrieve only 2,000 rows, the query had to scan through 700,000 rows, wasting precious time and resources. It was like looking for a specific document in a cluttered room instead of a well-organized filing cabinet.
We knew we had to intervene. Our solution? Replace the sluggish OR statement with the more efficient AND NOT statements.
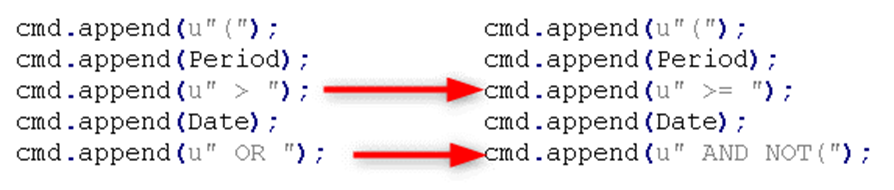
![]()
The selection condition was modified within the platform in the SDBL query, ensuring this optimization would apply to all supported DBMSs.
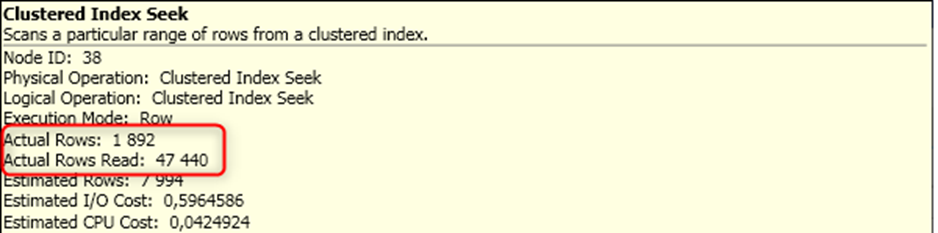
The results were nothing short of transformative. The number of rows read dropped dramatically, to just one-tenth of what it was before, and the query execution time improved significantly. It was a victory for optimization and a testament to the power of SDBL.
Data Restructuring: Change is in the Air (and in the Database)
It seems like application developers can't resist making changes. One minute they're happy with their object structures, and the next, they're itching to replace everything. New dimensions are added, resources are renamed, and objects are ruthlessly deleted, leaving a trail of database debris in their wake.
Migrating to a new configuration version with such dramatic changes requires a delicate touch and a robust plan. Without a safety net, data loss is very real (and very scary).
But fear not, for the 1C:Enterprise platform is prepared for such eventualities. We have a secret weapon: the data restructuring mechanism. This ingenious mechanism swoops in to save the day, ensuring a smooth and seamless transition to the new configuration without losing a single byte of data.
Picture this:
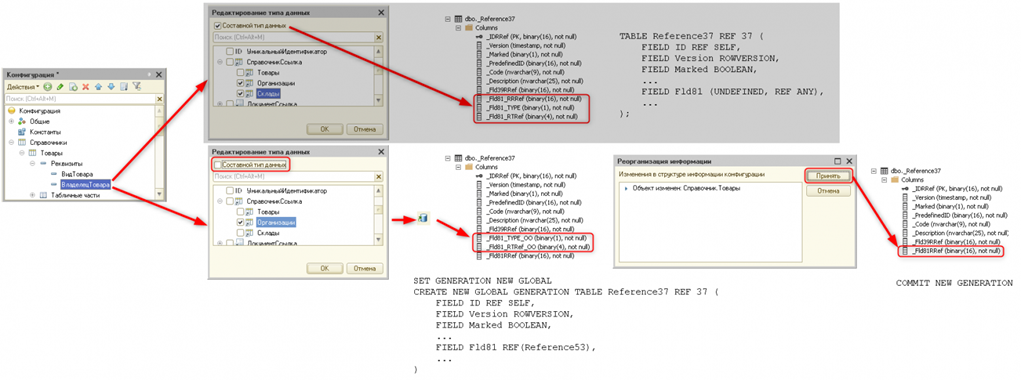
Let's break down the magic happening in this diagram. We have a Product catalog with a ProductOwner attribute, currently represented by a composite data type that can accept either Organization or Warehouse as its value. In the SDBL schema, it's defined as an attribute with a composite type, happily coexisting with its two possible values.
But then, a developer decides that ProductOwner should only accept Organization as its value. Perhaps Warehouse decided to go solo, or maybe migrated to a different server. Whatever the reason, ProductOwner is now a direct reference to the Organizations catalog, leaving Warehouse out in the cold.
When the time comes to update the database configuration, the platform springs into action. It creates a brand-new generation of the product table, using the SDBL CREATE NEW GENERATION statement. This new table reflects the updated ProductOwner attribute, with a direct reference to the Organizations table.
But what about those redundant columns previously used to accommodate the composite type? We wouldn't dream of just deleting them! They get special treatment: we mark them with _OO postfixes, sort of like giving them a retirement badge.
We also need to keep the user informed. The platform warns them about the changes to the Products catalog, just in case they were relying on the old structure. It's all about managing expectations, you know!
Now, if a product happened to be linked to a Warehouse as its owner, the platform would politely ask everyone to hold on a sec. We take data loss very seriously, so we have safeguards in place to avoid any mishaps. The user would simply need to update those products to have an Organization as the owner before moving on. It's like a database checkpoint, ensuring everything is in order before we proceed.
But let's be honest: such scenarios are typically avoided during the configuration design phase. We try to anticipate these types of changes and plan accordingly because who has time for data recovery headaches?
If the user decides to abandon the changes altogether (we've all had second thoughts), the platform is more than happy to oblige. It simply executes an SDBL ROLLBACK command, reverting the database configuration back to its previous state, like nothing ever happened.
But if the user decides to embrace change, the platform executes a COMMIT statement, ushering in the new era of the updated database. The redundant columns are finally laid to rest, and the ProductOwner attribute enjoys its new, simplified existence.
External Data Sources: Connecting the Unconnectable
The world of databases is vast and diverse, filled with a plethora of different systems, each with its quirks and peculiarities. While the 1C:Enterprise platform has a soft spot for certain DBMSs (we're looking at you, SQL Server, PostgreSQL, Oracle, and IBM DB2), we understand that sometimes you need to access data from other sources.
That's where our external data source mechanism comes in, like a bridge connecting different database islands. This handy feature allows us to retrieve data from any ODBC-compliant DBMS.
Let's say we need to access an employee table residing in an SQLite database.
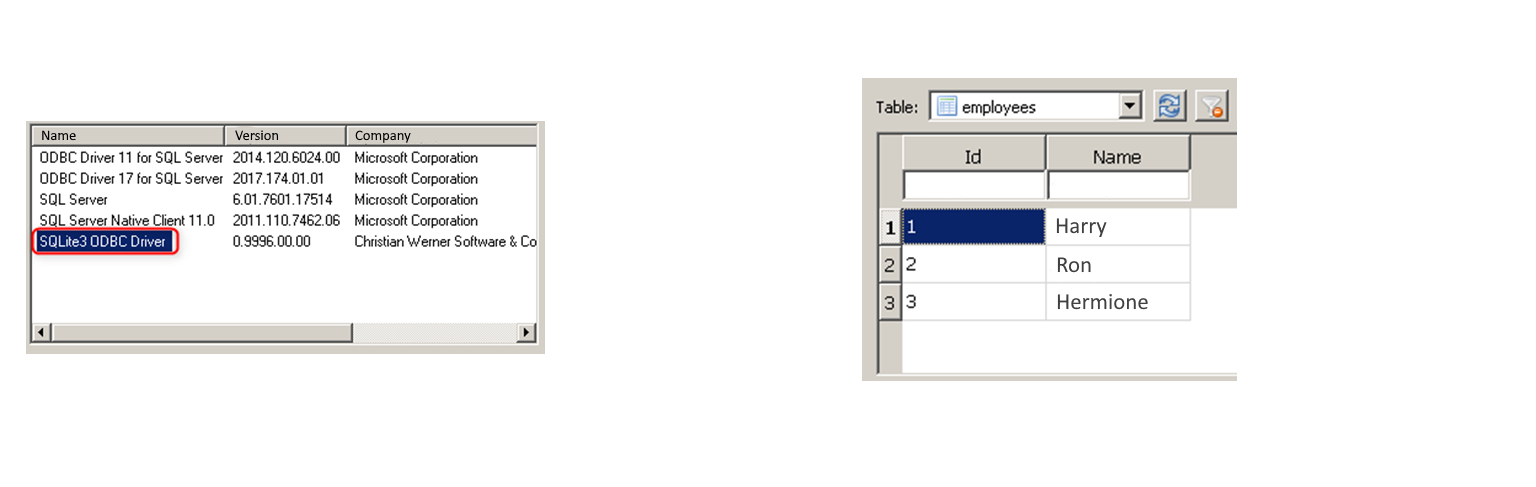
Normally, this would be a recipe for interoperability headaches. But not with 1C:Enterprise on our side!
We simply create an external data source, provide the database connection string (like a secret handshake), and select the tables and fields we're interested in. Then, using the power of the 1C:Enterprise language, we can retrieve the data we need as if by magic.
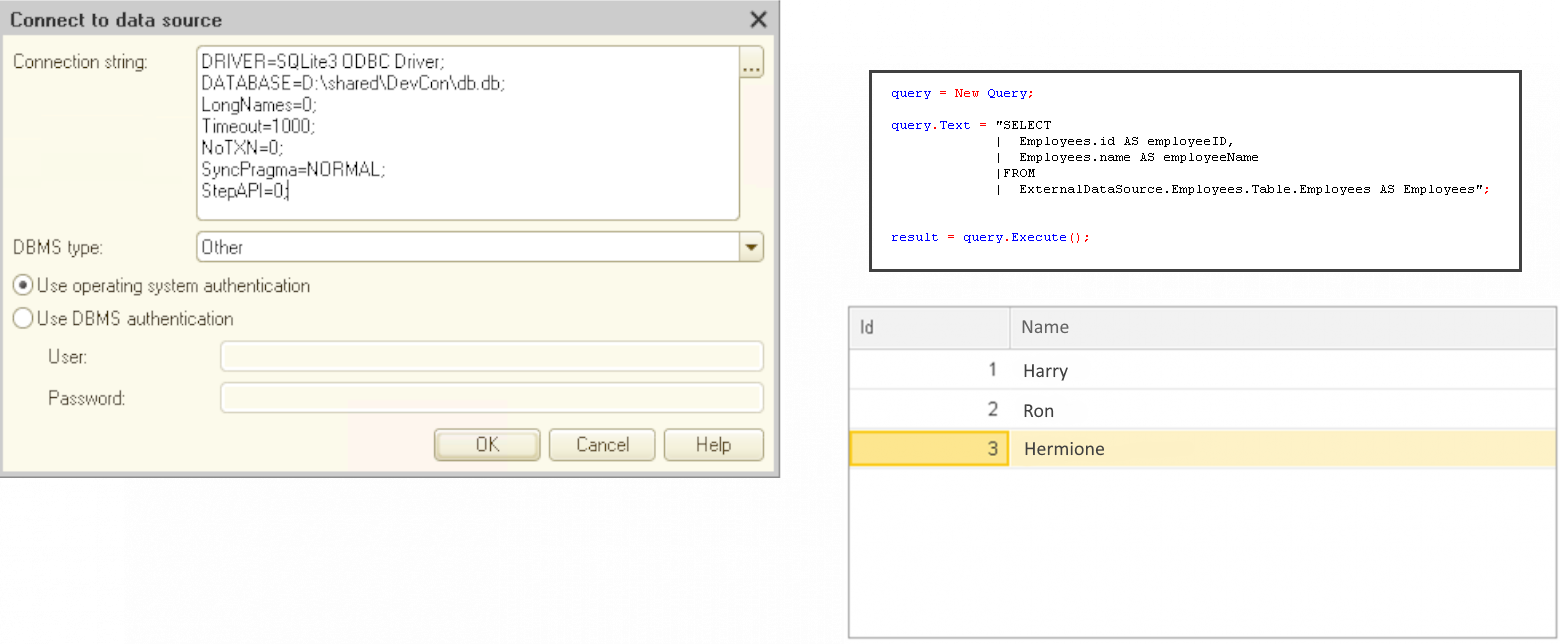
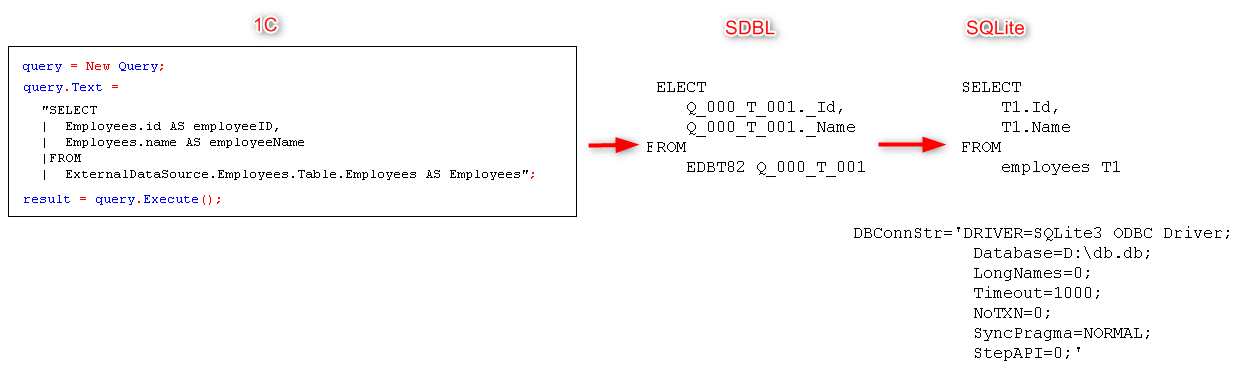
Behind the scenes, SDBL is hard at work, translating our 1C:Enterprise language query into a format that the external DBMS can understand. It's like having a universal translator for databases, breaking down barriers and enabling seamless communication.
Transaction Management: Keeping the Data Flowing Smoothly
Data locking and transaction isolation levels: two phrases that strike fear into the hearts of many developers. These concepts are crucial for maintaining data integrity and ensuring that concurrent transactions don't trip over each other, leading to data corruption and chaos.
Different DBMSs have their unique approaches to handling these complexities. Some rely on lock-based concurrency control, where transactions acquire locks on data, preventing others from accessing it until they're finished. It's like putting a reservation on a table at a restaurant: if it's locked, you have to wait your turn.
Others prefer a more optimistic approach, using versioning to create snapshots of the data at the beginning of each transaction. This allows multiple transactions to work on their own copies of the data simultaneously, without interfering with each other. It's like giving everyone their own personal sandbox to play in, preventing conflicts and promoting database harmony.
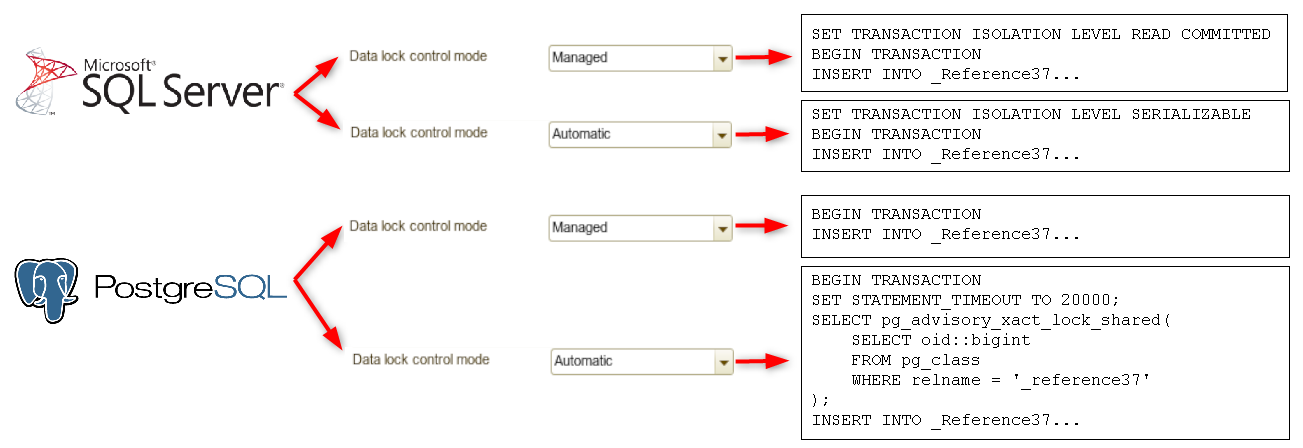
The 1C:Enterprise platform, being the overachiever that it is, offers its own managed data locking mechanism. This allows us to fine-tune locking behavior based on the specific needs of the application, striking a balance between performance and data integrity.
But the best part is that both application developers and platform developers are shielded from these complexities. Application developers can merrily write their queries in the 1C:Enterprise language, while platform developers can focus on SDBL, without having to worry about the intricacies of data locking and transaction isolation levels.
The platform handles these behind-the-scenes details, like a dedicated team of data traffic controllers, ensuring a smooth and efficient flow of information.
Conclusion: Living in a Multi-DBMS World, One Query at a Time
Seamlessly interacting with diverse database management systems is no longer a luxury: it's a necessity. In today's data-driven world, we need tools and platforms that can navigate the complex landscape of database technologies without breaking a sweat (or causing our developers to pull their hair out).
The 1C:Enterprise platform, with its custom SDBL language, intelligent translation and optimization mechanisms, and robust data restructuring capabilities, has risen to this challenge, providing a developer-friendly environment that embraces diversity and streamlines database interactions. By abstracting away complexity and empowering developers to focus on business logic, 1C:Enterprise has cemented its place as a leader in rapid business application development, proving that working with different DBMSs doesn't have to be a recipe for disaster. In fact, it can be a delightful symphony of ones and zeros.
So, as you embark on your next database adventure, remember the lessons learned from the 1C:Enterprise platform. Embrace diversity, optimize relentlessly, and never underestimate the power of a well-crafted query. The world of databases might be vast and complex, but with the right tools and a touch of humor, we can navigate its intricacies and emerge victorious, one query at a time.

Writen by


