This section describes the referential data usage specifics. Using queries to access this data can significantly improve the document posting performance.
We will use the "referential data" term to describe data that is stored in a database and accessed by means of 1C:Enterprise script objects of the Ref type: CatalogRef.<name>, DocumentRef.<name>, and so on. To simplify the explanation, we will use an example of getting a reference to a material or service type when posting a Services document.
Not all the data stored in the database is referential. This is due to the fact that within the 1C:Enterprise data structure there is a division between data that represents object entities (catalogs, charts of accounts, documents, and so on), and data that represents nonobject entities (information registers, accumulation registers, and so on).
From the platform perspective, a certain set of object-based data is defined not only by the field values but by the very fact of its existence as well. In other words, once you delete a set of object-based data from the database, you will not be able to get the system to the condition it had prior to the deletion. Even if you recreate the same set of object-based data with exactly the same field values, from the platform perspective it will be a DIFFERENT set of object-based data.
Such a set of object-based data, which is uniquely recognized by the platform, is referred to as a database object.
To ensure that the platform can distinguish one database object from another, each database object (a set of object-based data) has an internal identifier. Different database objects always have different identifiers. An identifier is stored together with the rest of the object data in a field named Ref.
Nonobject data is stored as records, and from the platform perspective it is fully defined by the values of the record fields. If you delete a certain record and then write a new one with exactly the same values in all the fields, the database will end up in the same state that it had before the deletion.
Therefore, since you can unambiguously point to each database object, you can store that pointer in fields within other database tables, select it in text boxes, use it as a query parameter when searching by reference, and so on.
All these scenarios use 1C:Enterprise script objects of the Ref type. In fact, this object only stores an internal identifier located in the Ref field.
If we use the Services document as an example, the field that stores the MaterialOrService attribute of the tabular section actually stores an internal identifier that points to an item in the MaterialsAndServices catalog (fig. 14.1).
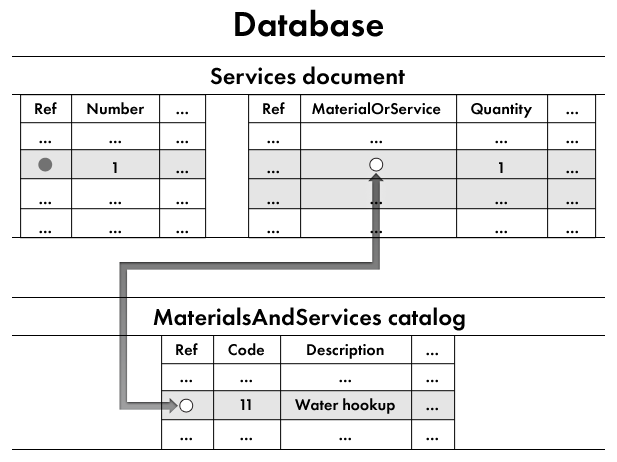
Fig. 14.1. Reference to a MaterialsAndServices catalog item
When the Posting event handler of the Services document assigns the value of the MaterialOrService tabular section attribute to some variable, it actually deals with 1C:Enterprise script object named DocumentObject.Services.
This object contains the values of all document attributes and all document tabular section attributes.
The script that accesses the object in listing 14.1 simply reads the data stored in that 1C:Enterprise script object from RAM (fig. 14.2).
Listing 14.1. Reference to an object attribute
Record.Material = CurRowMaterialsAndServices.MaterialOrService;
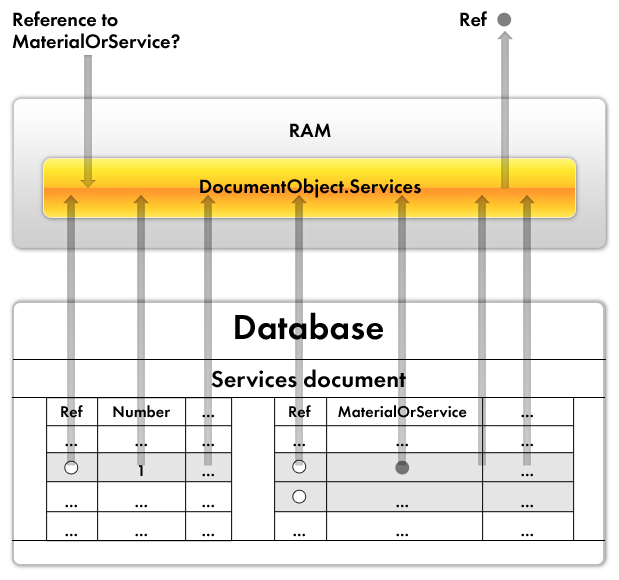
Fig. 14.2. Reading data from RAM
However, when you refer to a material or service type as an attribute of the catalog item that is referenced to in the document tabular section (listing 14.2), the following happens (fig. 14.3).
Listing 14.2. Reference to a reference attribute
If CurRowMaterialsAndServices.MaterialOrService.MaterialServiceType =
Enums.MaterialServiceTypes.Material Then
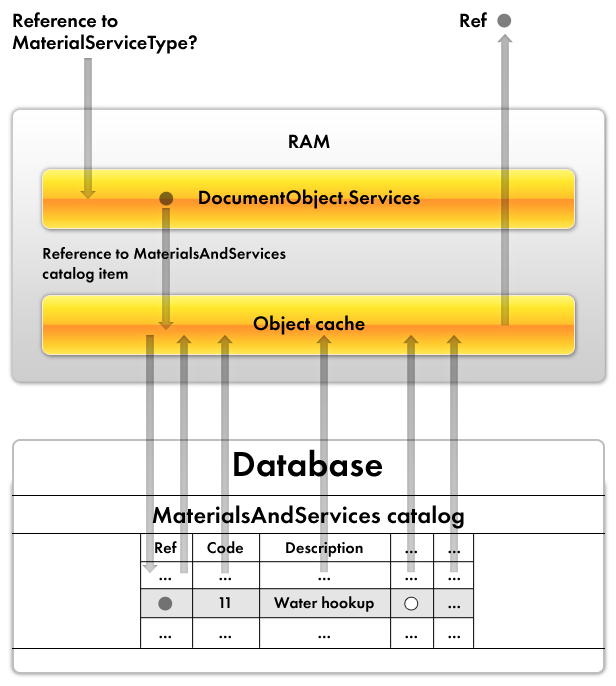
Fig. 14.3. Using object cache
Since the DocumentObject.Services object is only a reference to an item of the MaterialsAndServices catalog and there is no additional information about this item, the platform uses the reference to search the object cache for the data of the object that corresponds to that reference.
If the object cache does not contain the required data, the platform accesses the database to read all the data of the referenced object.
Once all the data stored in the attributes of the required catalog item and in the attributes of its tabular sections is read into the object cache, the object cache returns the requested reference stored in the MaterialServiceType attribute of the MaterialsAndServices catalog.
It is obvious that such query to the database takes far longer than simply reading from RAM. When a document is being filled interactively, such lags go unnoticed, compared to the user work speed. However, in a scenario with a large number of calculations (such as posting large documents containing thousands of rows), the time difference might be noticeable.
From the facts listed above, you can conclude that if the document posting algorithm uses only the data available in the document attributes and tabular sections, using the document register records wizard is totally sufficient (as was the case with the GoodsReceipt document).
However, if a posting algorithm includes the analysis of additional object attributes that are referenced in the document, and also requires the use of calculated register totals, you need to use queries to select data from the database faster.
The same is true for the execution of any parts of the program where performance is critical. Queries provide better options for reading the Infobase, they are capable of selecting only the required data in a single operation. That is why standard applied solutions almost never use 1C:Enterprise objects named CatalogSelection.<name>. They use database queries instead.
Next page: Improving posting performance